Tanto faz usar caminho ou table_id, pois no material está table_id e no vídeo está caminho para definir o ID do dataset de destino.
Você está vendo a versão anterior da nova experiência da Alura que estamos preparando para você. Em breve, ela ganha uma identidade visual novinha totalmente pensada em potencializar seus estudos!

Tanto faz usar caminho ou table_id, pois no material está table_id e no vídeo está caminho para definir o ID do dataset de destino.


Olá, William. Como vai?
Essa é uma excelente observação técnica e mostra o quanto você está atento aos detalhes do código tanto no vídeo quanto no material de apoio.
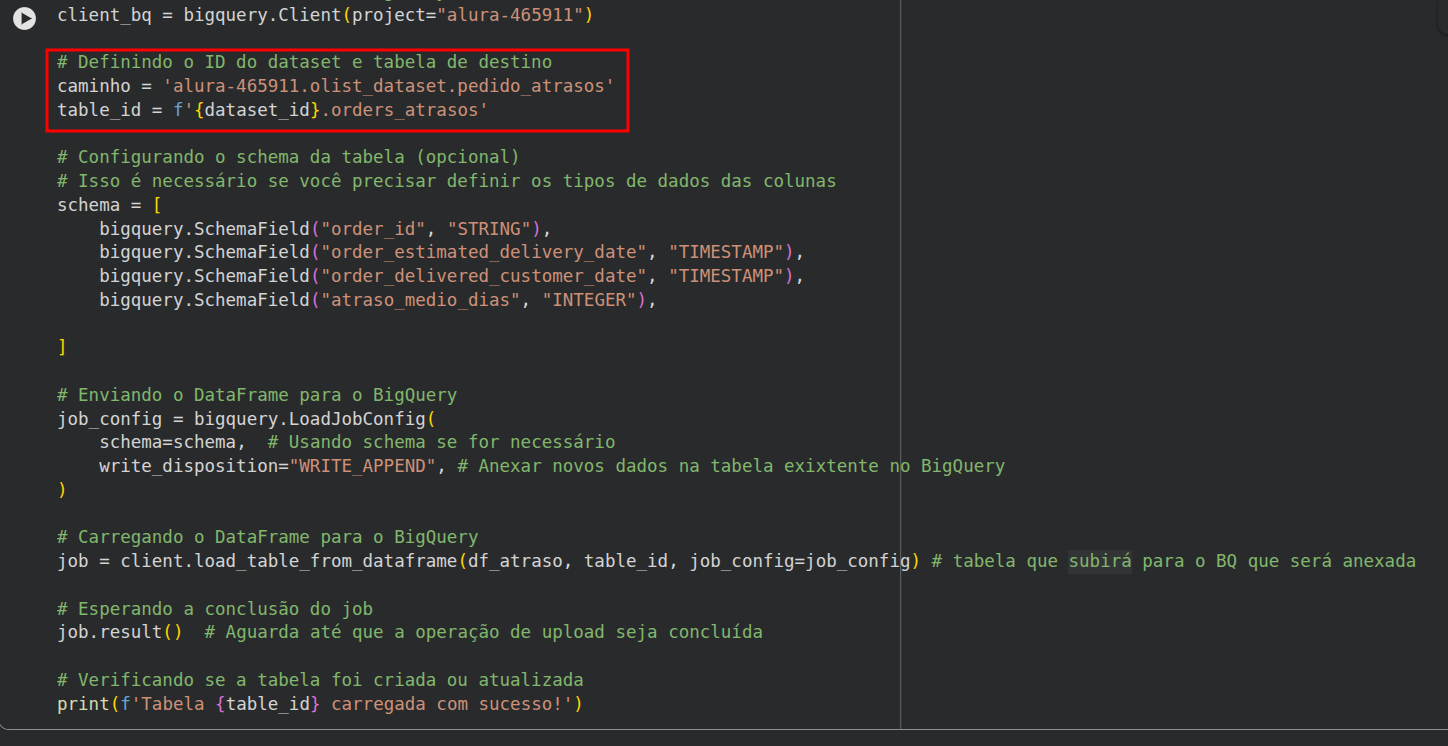
Olhando para a imagem do seu código, dentro do retângulo vermelho, conseguimos identificar exatamente o nó dessa questão. A resposta direta para a sua dúvida é: não, não tanto faz, porque do jeito que as variáveis estão declaradas na imagem, elas guardam caminhos ou referências diferentes, e isso pode quebrar a sua aplicação.
Vamos entender tecnicamente o que está acontecendo e como resolver isso de forma simples:
caminho: Ela aponta diretamente para uma tabela chamada pedido_atrasos dentro do dataset olist_dataset. O formato está completo seguindo o padrão projeto.dataset.tabela.table_id: Ela está tentando usar uma f-string (f'{dataset_id}.orders_atrasos'), mas repare que a variável dataset_id não foi definida anteriormente nesse trecho do código. Além disso, ela aponta para uma tabela diferente chamada orders_atrasos.Mais abaixo no seu script, na função de carregamento, você utilizou a variável table_id:
job = client.load_table_from_dataframe(df_atraso, table_id, job_config=job_config)
Para o BigQuery entender para onde enviar o seu DataFrame, o segundo argumento dessa função precisa receber uma string com o caminho completo da tabela de destino. Você pode escolher qualquer um dos dois nomes de variáveis (caminho ou table_id), desde que a variável escolhida tenha o texto correto e seja a mesma passada dentro da função.
Como boa prática, recomendo seguir o padrão que está documentado na biblioteca oficial do Google Cloud BigQuery para Python, utilizando o nome table_id com o caminho completo escrito diretamente, evitando criar variáveis que fiquem sem uso no código:
# Definindo o ID do projeto, dataset e tabela de destino de forma explícita
table_id = 'alura-465911.olist_dataset.pedido_atrasos'
# Enviando o DataFrame para o BigQuery usando a variável correta
job = client.load_table_from_dataframe(df_atraso, table_id, job_config=job_config)
Dessa forma, eliminando a linha da variável caminho e definindo o endereço completo diretamente na table_id, seu código fica limpo, padronizado com o material e livre de erros de execução por variáveis indefinidas.
Espero que possa ter lhe ajudado!