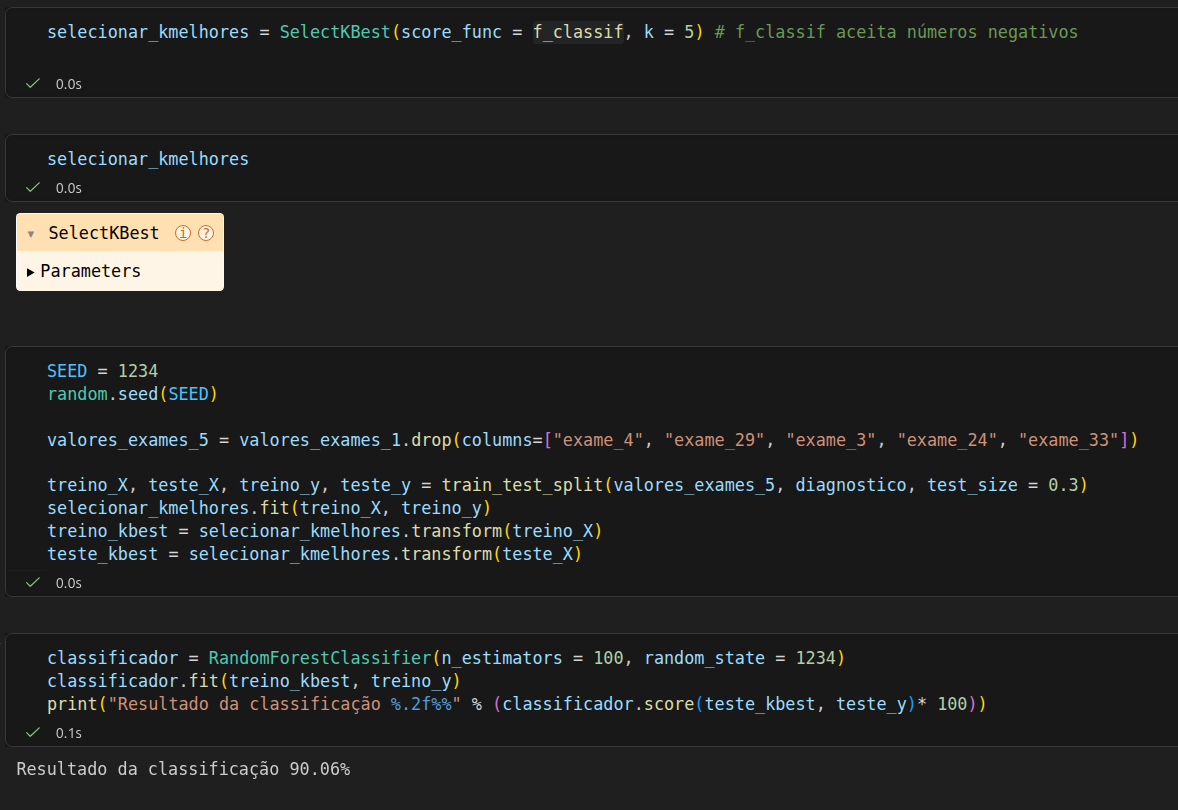
Na seleção eu mudei a score_func para f_classif, pois a passada na aula estava dando erro, devido a atualizações de biblioteca e ao aplicar a semente aleatória na separação de treino e teste meu score caiu um pouco o valor:
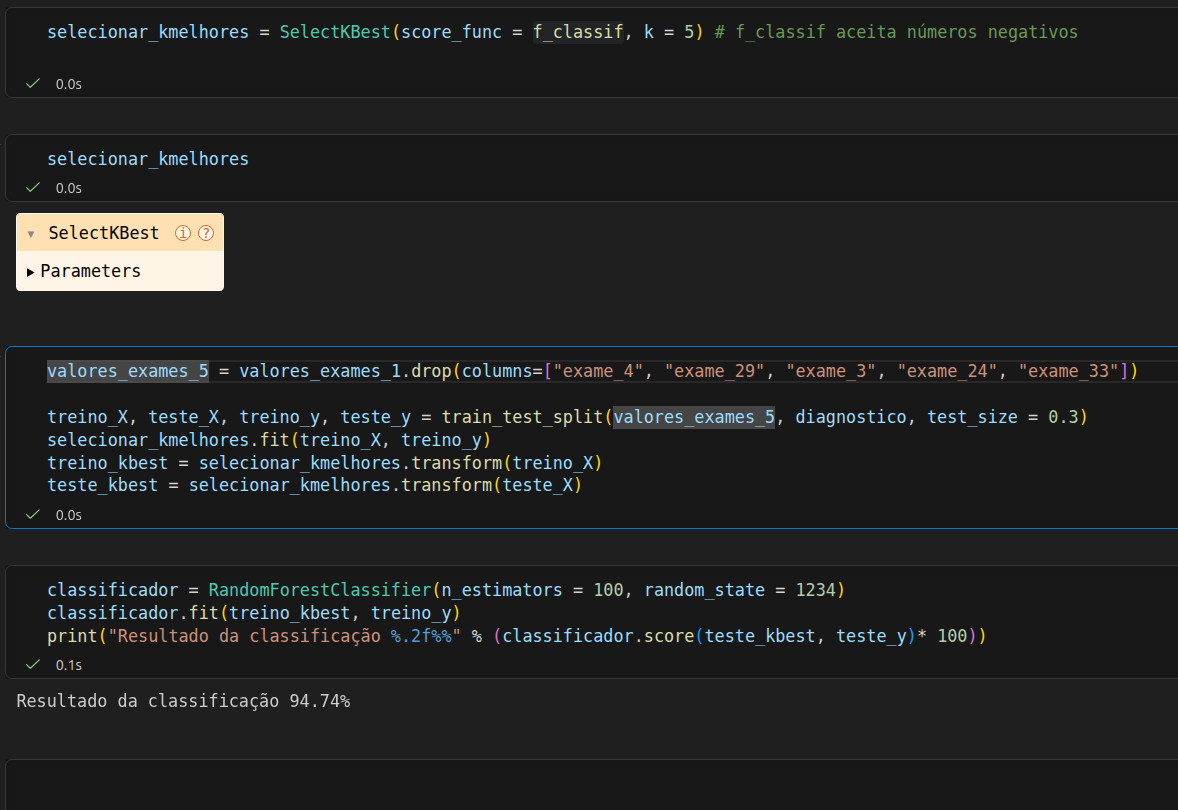
Sem a semente:
Você está vendo a versão anterior da nova experiência da Alura que estamos preparando para você. Em breve, ela ganha uma identidade visual novinha totalmente pensada em potencializar seus estudos!

Na seleção eu mudei a score_func para f_classif, pois a passada na aula estava dando erro, devido a atualizações de biblioteca e ao aplicar a semente aleatória na separação de treino e teste meu score caiu um pouco o valor:
Sem a semente:


Olá William, tudo bem?!
Parabéns pela iniciativa de buscar o f_classif como alternativa.
Ao trocar para o f_classif (ANOVA), você usou uma técnica que aceita números negativos e foca na variância entre as médias das classes. Como o cálculo matemático é diferente, as 5 "melhores" colunas escolhidas pelo f_classif podem não ser as mesmas 5 que o chi2 escolheria. Isso, por si só, já altera o resultado final da acurácia.
Quando a semente aleatória, repare que, entre o seu primeiro e segundo print, a acurácia subiu de 90.06% para 94.74%. O train_test_split separa os dados de forma aleatória. Sem uma semente fixa (random_state), cada vez que você roda o código, o modelo treina com um grupo de dados e testa com outro totalmente diferente.
No seu segundo caso, a divisão dos dados pode ter deixado exemplos "mais fáceis" no conjunto de teste, ou o modelo conseguiu generalizar melhor com aquele grupo específico de treino.
Quando reduzimos drasticamente o número de features (de dezenas para apenas 5), o modelo se torna muito mais sensível. Qualquer pequena mudança na escolha dessas colunas ou na forma como os dados são divididos causa grandes oscilações no resultado.
Com o f_classif, você criou um novo experimento técnico. Seu resultado de 94.74% é, inclusive, muito bom!
Continue experimentando, essa sensibilidade ao ajuste de parâmetros é o coração do aprendizado de máquina!
Qualquer dúvida que surgir, compartilhe no fórum. Abraços e bons estudos!