Oi, Ingrid! Tudo bem?
Peço desculpas por demorar a te responder.
Durante uma consulta SQL, para que o comando GROUP BY funcione de forma efetiva, todas as colunas indicadas no SELECT precisam fazer parte do critério de agrupamento. Essa mesma regra também deve ser levada em consideração quando criamos uma subconsulta.
De maneira genérica, precisamos ter algo semelhante ao script abaixo:
SELECT X.coluna_1, X.coluna_2, X.CONTADOR FROM
(SELECT coluna_1, coluna_2, COUNT(*) AS CONTADOR FROM tabela
GROUP BY coluna_1, coluna_2)) X
Note que, tanto no SELECT da sub consulta quanto no GROUP BY chamamos os campos coluna_1 e coluna_2, conforme a exigência comentada anteriormente. Por fim, para visualizar os registros de coluna_1 e coluna_2, também escrevemos X.coluna_1 e X.coluna_2 no SELECT geral.
Sabendo disso, podemos trazer essa mesma ideia para a empresa de sucos de fruta. A fim de "tirar a prova" com relação ao ano de 2016, teremos que executar o script SQL abaixo:
SELECT X.CPF, X.ANO, X.CONTADOR FROM
(SELECT CPF, YEAR(DATA_VENDA) AS ANO, COUNT(*) AS CONTADOR FROM notas_fiscais
WHERE YEAR(DATA_VENDA) = 2016
GROUP BY CPF, ANO) X WHERE X.CONTADOR > 2000;
Para uma melhor compreensão, separei os comandos em duas partes, observe:
- Sub consulta:
- No
SELECT, selecionamos o ano de DATA_VENDA e demos o apelido de ANO para ele; - Após isso, adicionar
ANO ao GROUP BY, especificando que ele também deve ser um dos critérios de agrupamento juntamente com o CPF.
- Consulta:
- No
SELECT, adicionamos mais uma coluna identificada por X.ANO, a qual apresentará o ano de DATA_VENDA, conforme definimos na subconsulta.
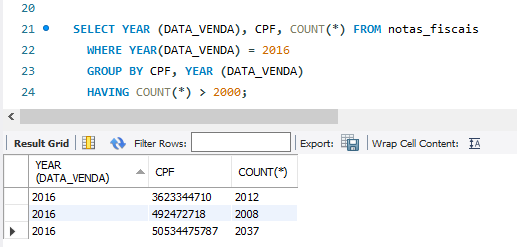
Dessa maneira, Ingrid, chegaremos no seguinte resultado:
| CPF | ANO | CONTADOR |
|---|
| 3623344710 | 2016 | 2012 |
| 492472718 | 2016 | 2008 |
| 50534475787 | 2016 | 2037 |
E olha só, realmente filtramos apenas as informações de 2016!
Espero ter ajudado com a explicação! Se surgirem novas dúvidas, fico à disposição.
Abraços, Ingrid!
Caso este post tenha lhe ajudado, por favor, marcar como solucionado ✓.