Olá, estou com dúvida em como renomear o dataframe criado na aula de uma forma diferente.
Durante a aula, o professor chegou a renomear o dataframe criado dos alunos de Estatística Básica, gerando um DataFrame com representação semelhante a esta:
| Alunos do curso de Estatística básica | |
|---|---|
| id_aluno | |
| 310 | JULIANA |
| 163 | LUCIANA |
| 338 | DEBORA |
| 249 | ANGELA |
| 32 | SARA |
| 62 | EUNICE |
| 237 | ZILDA |
| 230 | CARLOS |
Eu gostaria de fazê-lo um pouco diferente, de forma que o texto ' Alunos do curso de Estatística básica' continuasse em um patamar superior e quase centralizado (como se fosse um título), enquanto na linha de baixo eu ainda tivesse o 'id_aluno', seguido de 'Nome'. Algo parecido com isso:
| Alunos do curso de Estatística básica | |
|---|---|
| Id aluno | Nome |
| 310 | JULIANA |
| 163 | LUCIANA |
| 338 | DEBORA |
| 249 | ANGELA |
| 32 | SARA |
| 62 | EUNICE |
| 237 | ZILDA |
| 230 | CARLOS |
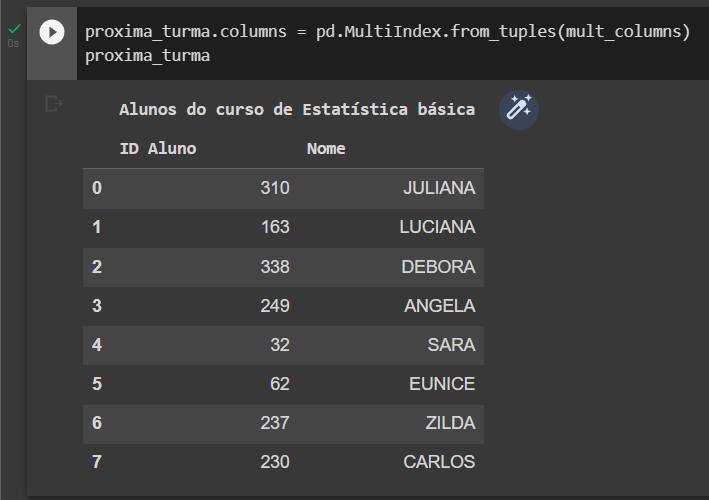
Tentei algumas formas mas não consegui chegar nesse modelo. O modelo mais próximo que obtive foi:
| Alunos do curso de Estatística básica | |
|---|---|
| Id aluno | Nome |
| 310 | JULIANA |
| 163 | LUCIANA |
| 338 | DEBORA |
| 249 | ANGELA |
| 32 | SARA |
| 62 | EUNICE |
| 237 | ZILDA |
| 230 | CARLOS |
Onde o texto deixou de estar acima do 'Nome', como eu desejo. O código utilizado foi:
proxima_turma.columns.name = 'Alunos do curso de Estatística básica:'
proxima_turma.index.name = 'Id aluno'
proxima_turma.rename({'nome': 'Nomes:'}, inplace = True, axis = 1)
Vi que talvez conseguiria chegar na forma desejada utilizando de multi index, mas não consegui entender uma forma de usar e colocar meu dataframe desta maneira. Como eu poderia modelá-lo dessa forma?