Olá, Aristóteles. Como vai?
Parabéns pela resolução completa da sequência de desafios! É muito bacana ver o seu caderno do Google Colab tão bem organizado. Você demonstrou um domínio excelente das operações vetorizadas e das técnicas de indexação booleana da biblioteca Pandas, que são ferramentas fundamentais no dia a dia de um Cientista de Dados.
A sua linha de raciocínio foi impecável do começo ao fim:
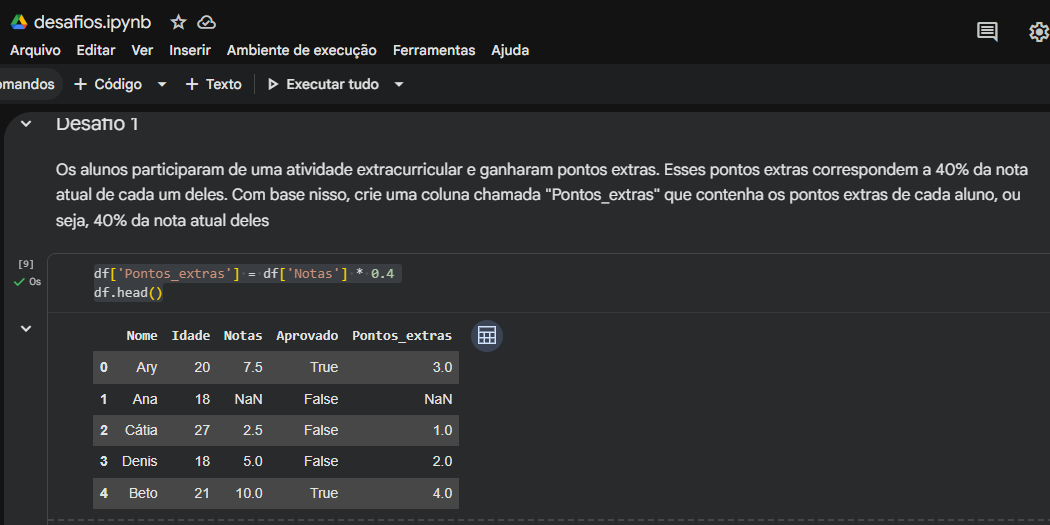
- No Desafio 1, a multiplicação direta
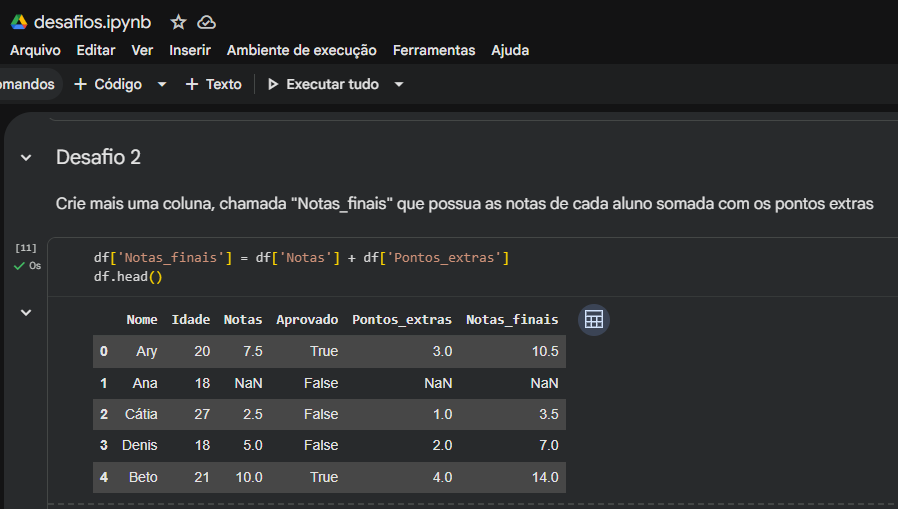
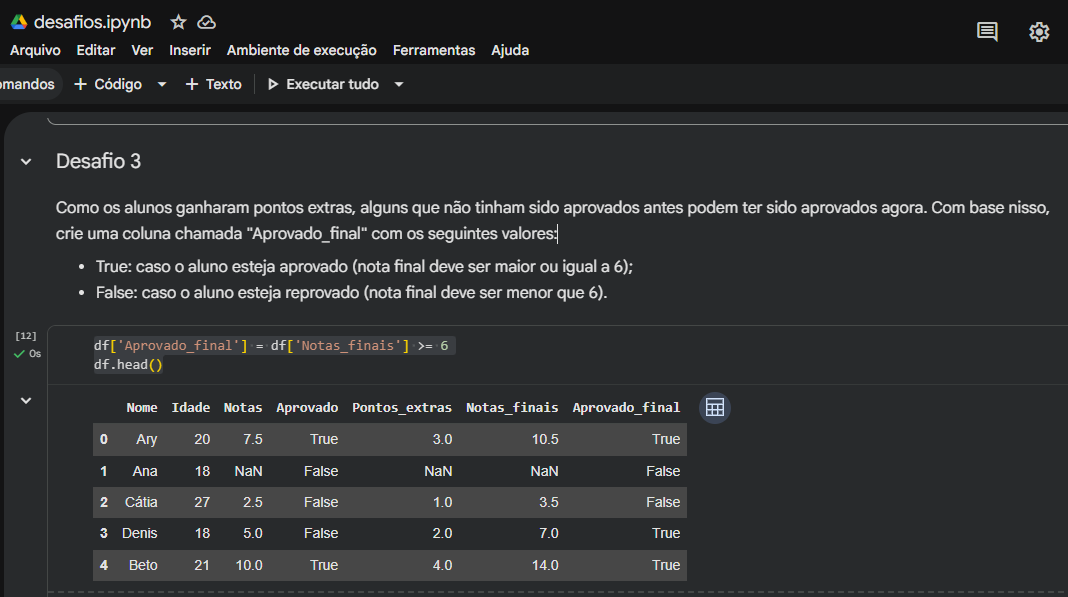
df['Notas'] * 0.4 calculou os 40% com perfeição. - No Desafio 2 e 3, você realizou somas e comparações lógicas de forma vetorizada, o que é o padrão ideal de performance no Pandas (evitando loops desnecessários).
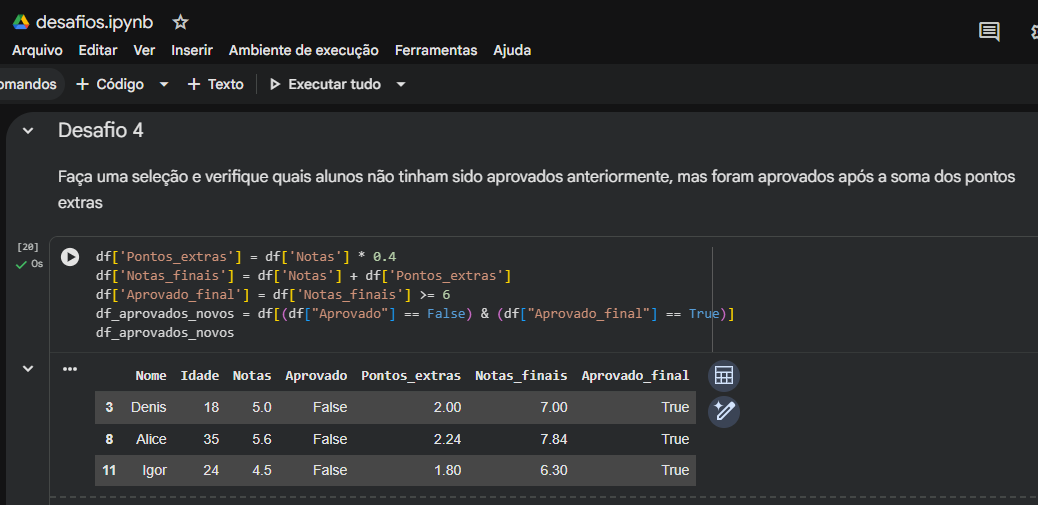
- No Desafio 4, o uso do operador lógico
& (E) para cruzar os critérios e encontrar os alunos que mudaram de status (Aprovado == False e Aprovado_final == True) fechou o exercício com chave de ouro, isolando cirurgicamente os registros do Denis, da Alice e do Igor.
Para enriquecer ainda mais o seu aprendizado sobre manipulação de dados com o Pandas, quero compartilhar duas observações técnicas bem importantes sobre os bastidores de dados faltantes e boas práticas:
1. O comportamento do Pandas com valores NaN (Not a Number)
Se você reparar na linha correspondente à aluna Ana (índice 1) nos resultados dos Desafios 1, 2 e 3, a nota original dela era um NaN (um dado que estava em branco na base original).
Repare que qualquer operação matemática feita com um valor nulo (NaN * 0.4 ou NaN + Pontos_extras) resulta automaticamente em outro NaN. Além disso, na hora da checagem lógica do Desafio 3 (df['Notas_finais'] >= 6), o Pandas converteu o valor da Ana para False, porque um dado ausente não consegue satisfazer uma condição matemática.
No mundo real, antes de realizar operações como essas, uma boa prática de mercado é tratar esses valores nulos para que eles não distorçam as suas análises. Você pode fazer isso de duas formas principais:
- Preenchimento: Substituir os nulos por zero usando o método
.fillna(0). - Descarte: Remover as linhas que possuem dados em branco usando o método
.dropna().
2. Otimização de Código (Evitando Redundância)
No seu Desafio 4, dentro da célula de execução, você acabou reescrevendo as três linhas de código que já tinham sido executadas nos desafios anteriores:
df['Pontos_extras'] = df['Notas'] * 0.4
df['Notas_finais'] = df['Notas'] + df['Pontos_extras']
df['Aprovado_final'] = df['Notas_finais'] >= 6
Como o Google Colab armazena o estado do seu DataFrame df na memória do navegador após cada clique em "Executar", essas colunas já existiam e estavam salvas no seu objeto. Portanto, na célula do Desafio 4, você poderia ter colocado apenas as duas linhas finais:
# Como o DataFrame já foi modificado nas células de cima, basta filtrar:
df_aprovados_novos = df[(df["Aprovado"] == False) & (df["Aprovado_final"] == True)]
df_aprovados_novos
Isso poupa processamento da máquina e deixa o seu caderno de estudos muito mais limpo e direto.
Parabéns pelo capricho no código, pelo uso correto das estruturas e pelo ótimo compartilhamento de conhecimento aqui no fórum. Continue com essa constância fantástica!
Espero que possa ter lhe ajudado!