Olá, Aristóteles. Como vai?
Sua resolução ficou excelente! Você demonstrou um domínio muito bom dos métodos de tratamento, filtragem e exportação de dados do Pandas. Os prints anexados comprovam que as operações foram executadas com sucesso e retornaram exatamente o esperado.
Gostaria de destacar e parabenizar alguns pontos fortes da sua solução:
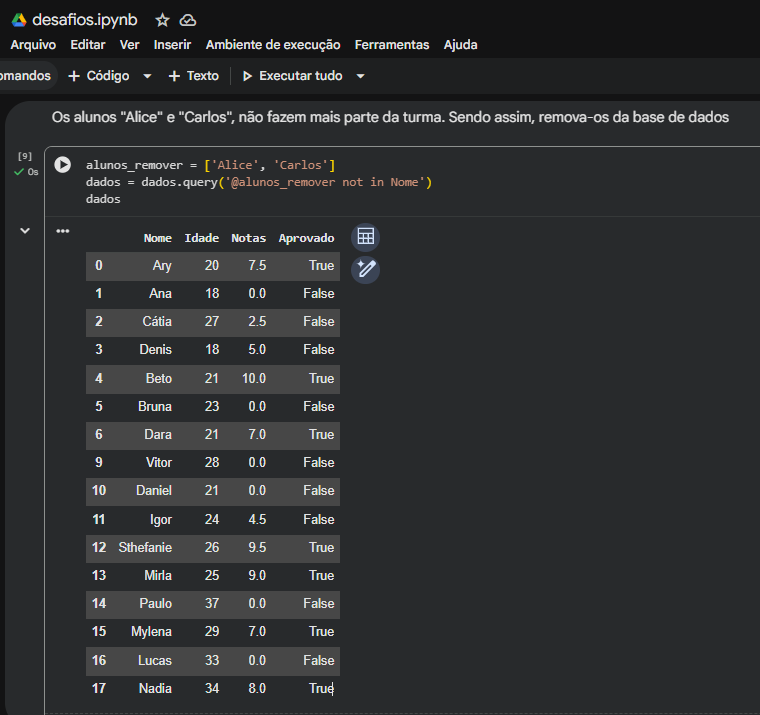
- Uso do método
.query() no item 2: Utilizar a sintaxe not in com o operador @ para referenciar a lista externa (@alunos_remover) é uma das formas mais elegantes e legíveis de aplicar filtros no Pandas. Deixou o código muito limpo! - Exportação correta com
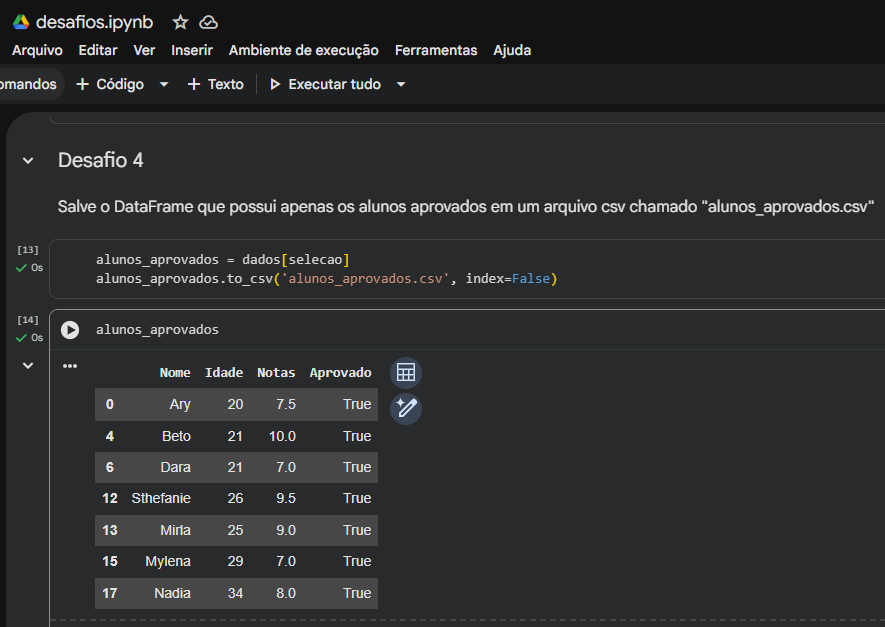
index=False no item 4: Essa é uma excelente prática no dia a dia da ciência de dados. Deixar o índice padrão do Pandas ser salvo no CSV costuma criar uma coluna sem nome ("Unnamed: 0"), o que polui o arquivo final. O seu arquivo ficou perfeito.
Como o objetivo do fórum é debatermos boas práticas e refinamentos técnicos, gostaria de levantar dois pontos de atenção bem importantes sobre as etapas 1 e Extra da sua resolução:
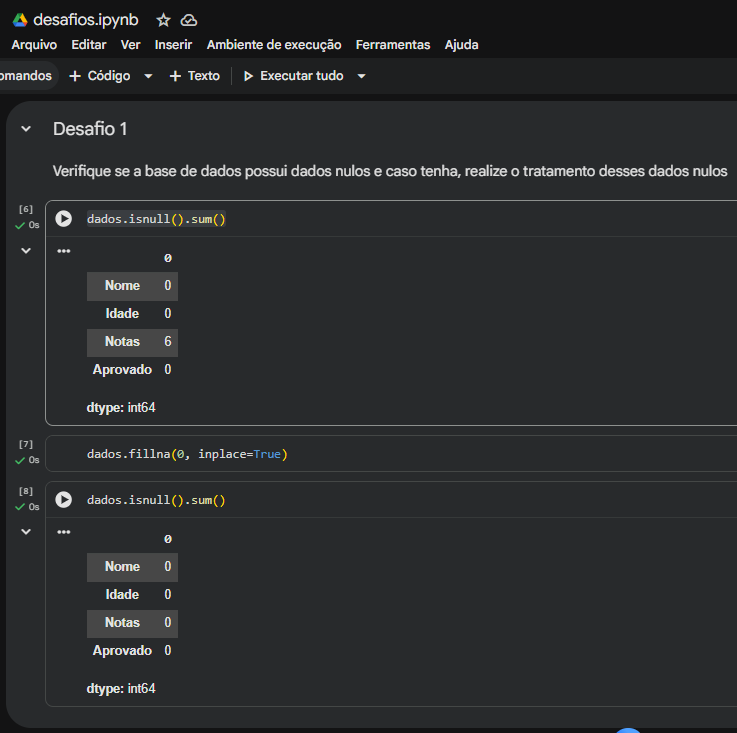
1. Detalhe no item 1: Identificar vs. Tratar dados nulos
Na primeira questão, você rodou o comando dados.isnull().sum(), que mapeia perfeitamente a quantidade de valores nulos por coluna. Pelos prints, notamos que a coluna "Notas" possuía alguns valores ausentes. Lembre-se de que além de verificar, o enunciado pedia para realizar o tratamento.
Uma boa prática para essa base de alunos seria preencher as notas nulas com zero (caso tenham faltado às avaliações) ou removê-los usando o método .fillna() ou .dropna(). Exemplo:
# Preenchendo notas nulas com 0 e aplicando a alteração na base
dados['Notas'] = dados['Notas'].fillna(0)
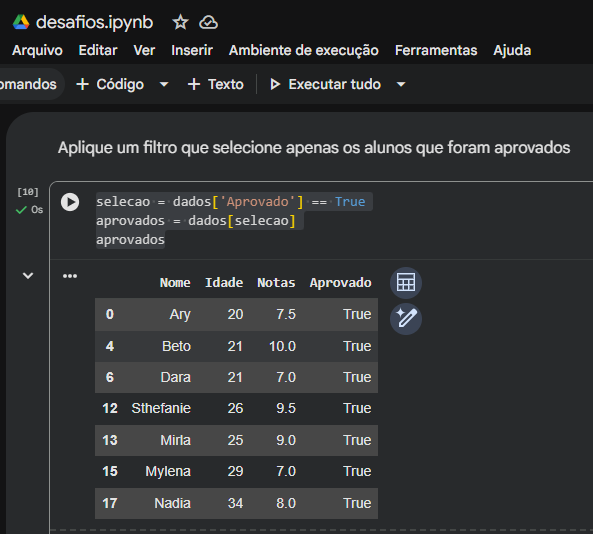
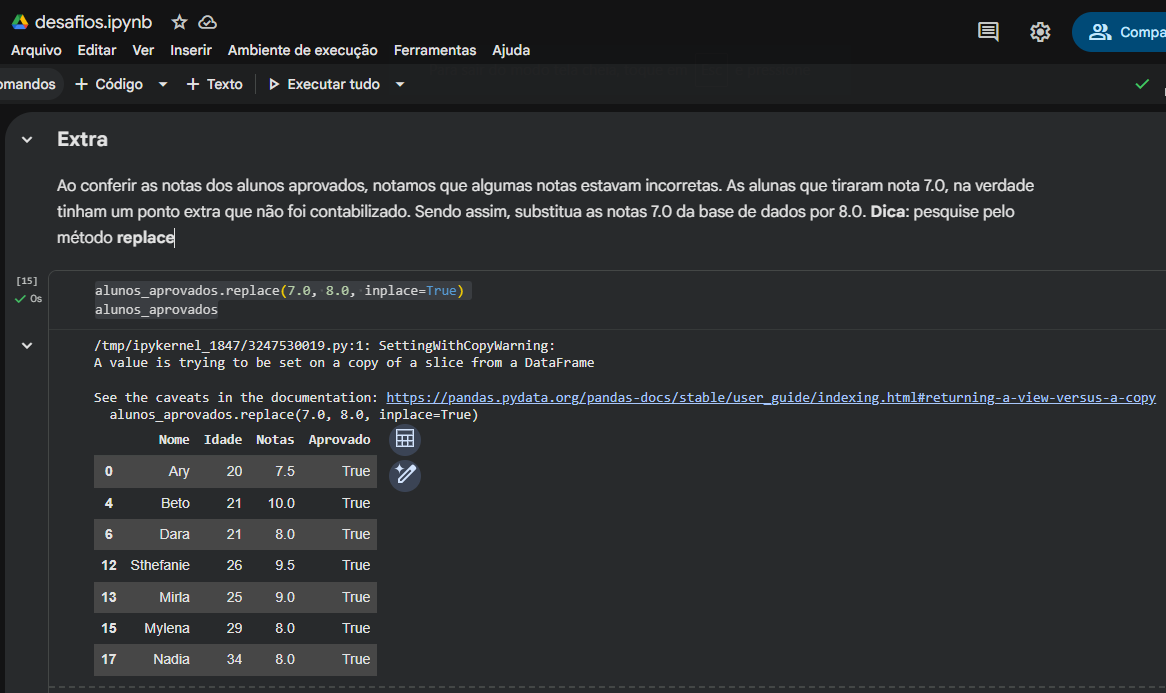
2. O temido SettingWithCopyWarning no bloco Extra
No item Extra, você aplicou o método .replace(..., inplace=True) diretamente na variável alunos_aprovados. Se você reparar nas imagens dos seus notebooks, o Pandas provavelmente exibiu um aviso em uma caixa vermelha chamado SettingWithCopyWarning.
Isso acontece porque, no item 3, a variável alunos_aprovados foi criada como uma fatia (ou visualização) do DataFrame original (dados[selecao]). Quando você usa inplace=True nela, o Pandas fica confuso se deve alterar apenas a cópia ou o DataFrame original, o que pode gerar comportamentos inesperados.
Para evitar esse aviso e garantir que seu código seja robusto, a boa prática indica usar o método .copy() explicitamente na criação do subconjunto ou isolar a coluna na hora de substituir. Veja a forma ideal:
# 3. Criando explicitamente uma cópia isolada na memória
alunos_aprovados = dados[dados['Aprovado'] == True].copy()
# Extra. Agora você pode modificar sem riscos de avisos do Pandas
alunos_aprovados['Notas'] = alunos_aprovados['Notas'].replace(7.0, 8.0)
Parabéns pelo excelente ritmo nos exercícios e pela organização visual do seu código. Compartilhar as telas com os resultados ajuda muito a comunidade a acompanhar sua evolução!
Espero que possa ter lhe ajudado com esses insights extras!