Olá Marcos, tudo bem?
Peço desculpas pela demora no retorno.
Diferentes de outros bancos de dados, o Oracle tem uma tabela interna que contém uma ordenação do alfabeto bem diferente do alfabeto que conhecemos, a tabela ASC. Nelas, os valores são classificados de forma numérica e os caracteres especiais também são incluídos. Outro ponto que também é importante é o idioma definido no seu banco de dados, pois idiomas diferentes têm ordens de classificação diferentes. Então, quando realizamos as consultas, o Oracle leva em consideração essa ordem numérica da tabela ASC e o idioma do banco de dados.
Porém, no Oracle existem alguns parâmetros que são utilizados para definir as configurações de data, número, moeda e idioma nacionais, são os parâmetros NLS (National Language Support - Suporte ao idioma nacional). Você pode ver quais as informações dos parâmetros NLS do seu banco de dados com a seguinte consulta:
SELECT * FROM NLS_DATABASE_PARAMETERS;
Entre os parâmetros NLS, existem dois que são responsáveis por realizar a classificação linguística do banco de dados, ou seja, definem como será feita a classificação dos dados no momento de retornar o resultado, esses parâmetros são o NLS_SORT e NLS_COMP
- NLS_SORT: Especifica o tipo de classificação para dados de caracteres, aceita como valor BINARY ou qualquer nome de classificação linguística válido e seu valor padrão deriva do parâmetro NLS_LANGUAGE, que é responsável por especificar o idioma padrão do banco de dados.
- NLS_COMP: Afeta o comportamento de comparação das operações SQL e aceita três valores, o BINARY, LINGUISTIC ou ANSI para versões anteriores. Por padrão o seu valor é o BINARY.
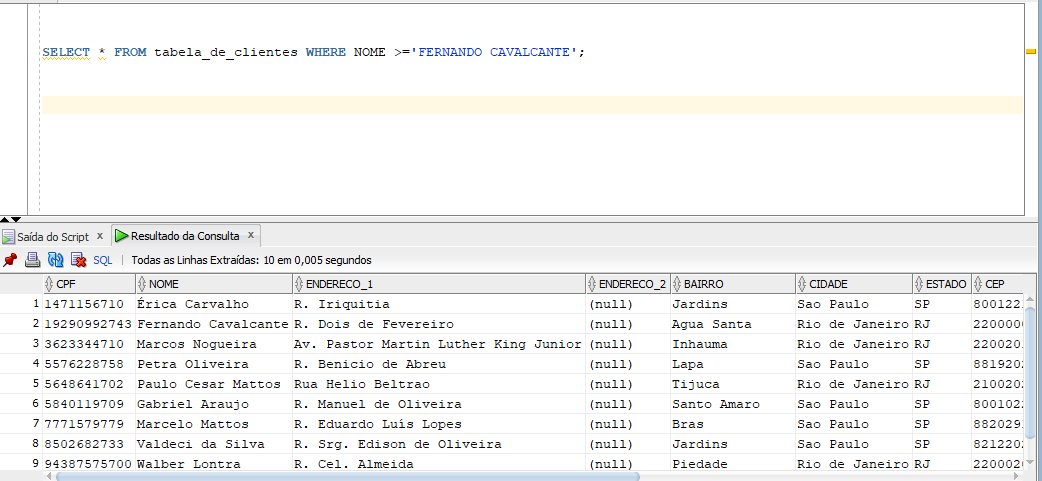
Ao utilizar o valor BINARY, a comparação linguística é feita de forma binária, ou seja, baseia-se nos valores numéricos da tabela ASC. Já ao utilizar o valor LINGUISTIC A comparação é feita de forma linguística, ou seja, baseia-se nos valores seguindo a ordem alfabética.
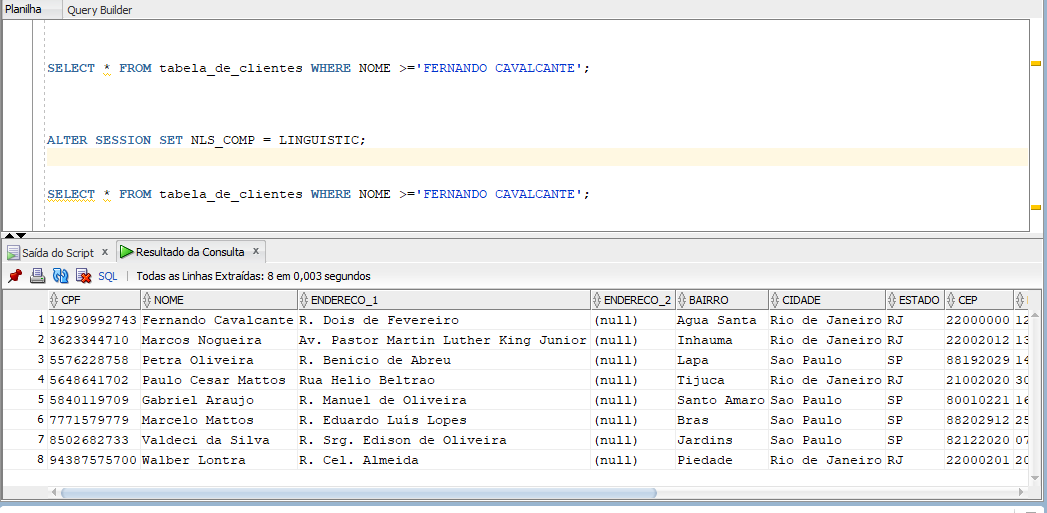
Para que seja feita uma comparação linguística, o parâmetro NLS_COMP precisa estar definido como LINGUISTIC. Assim, será realizada uma comparação linguística seguindo a ordem alfabética.
Então, você pode alterar o valor do NLS_COMP para a sessão atual da seguinte forma:
ALTER SESSION SET NLS_COMP = LINGUISTIC;
- O comando antes de alterar o NLS_COMP para LINGUISTIC
- O comando após alterar o NLS_COMP para LINGUISTIC
Vou deixar aqui para você dois links de referência para consultas futuras onde há um maior detalhamento sobre os parâmetros NLS_SORT e NLS_COMP e sobre as Classificações e que podem ajudar a esclarecer sobre este assunto.
Espero ter ajudado, qualquer dúvida é só falar e bons estudos!


