Olá a todos!
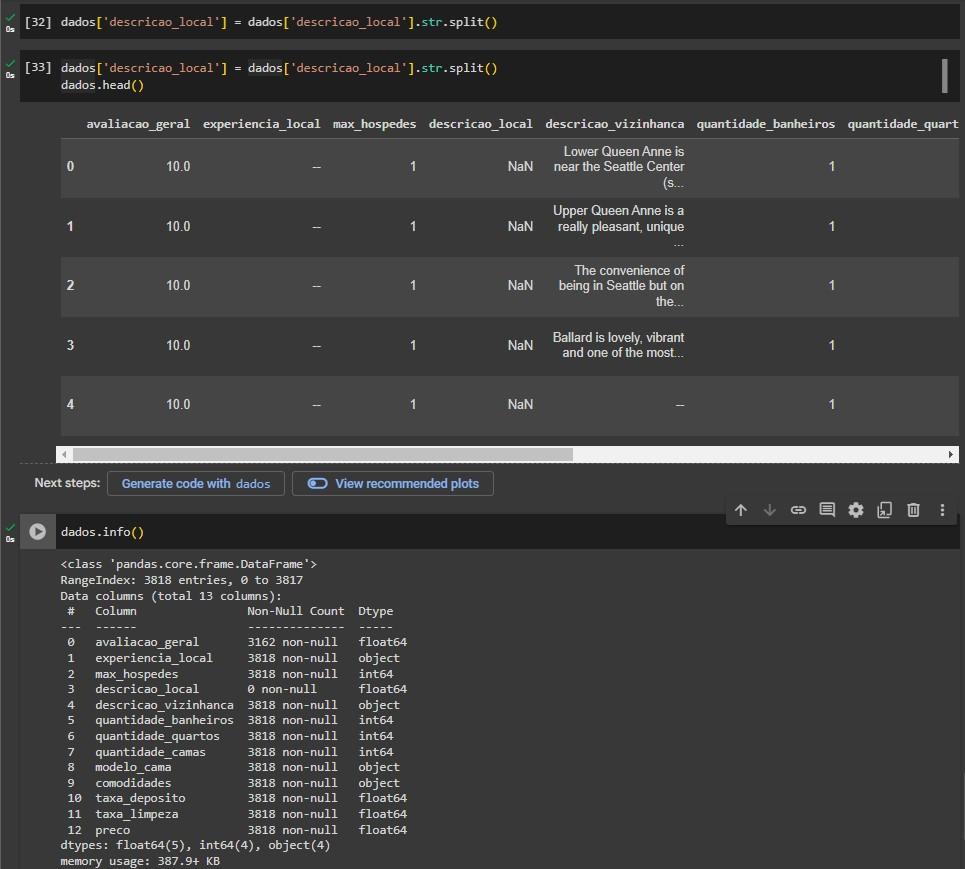
Ao aplicar o método .split() a coluna dados['descricao_local'], a coluna ficou como float, e no dataframe fica como NaN!
Você está vendo a versão anterior da nova experiência da Alura que estamos preparando para você. Em breve, ela ganha uma identidade visual novinha totalmente pensada em potencializar seus estudos!

Olá a todos!
Ao aplicar o método .split() a coluna dados['descricao_local'], a coluna ficou como float, e no dataframe fica como NaN!


Oii, Vinicius! Tudo bem?
Essa diferença ocorreu devido à execução duplicada do código, que acaba gerando um conflito de informações e resultado em NaN.

Para solucionar o problema, recomendo Inicializar o notebook e exatamente nesta célula, apague a primeira.

Feito isso, execute novamente a célula e observe se o código funciona como esperado. Qualquer dúvida, conte conosco.
Bons estudos, Vinicius!
Olá Nathalia! Muito obrigado pela ajuda, o bug era devido a este erro mesmo!