Olá!
Alguém poderia me ajudar?
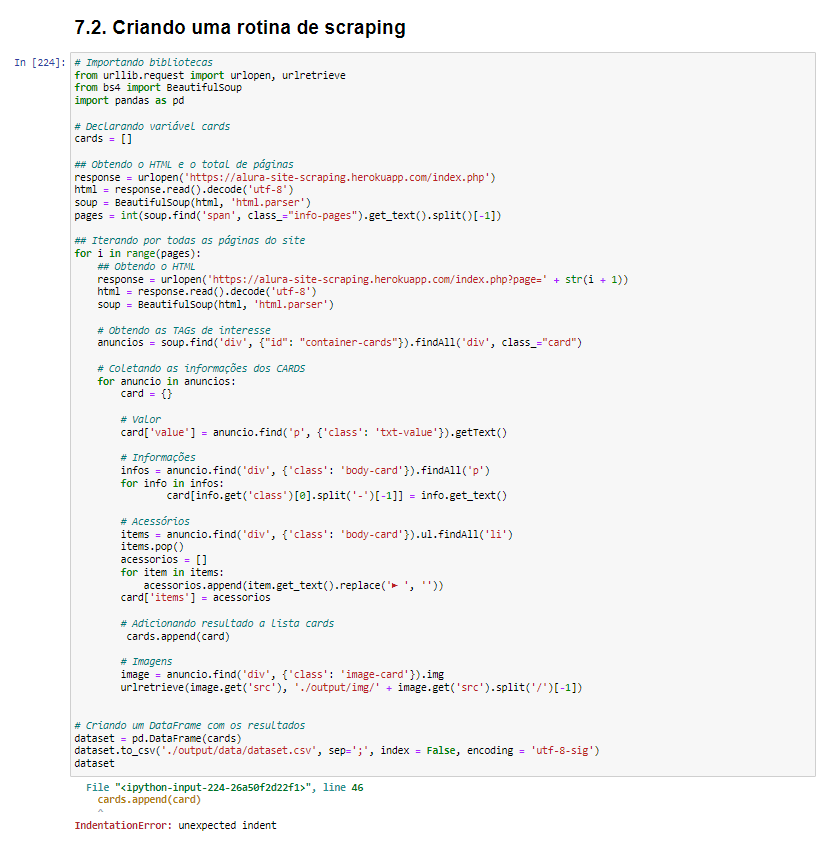
No último vídeo da aula 7, de Web Scraping, eu tentei gerar o código tal como foi feito pelo professor. A ideia era gerar uma rotina de scraping de dados das páginas do url fornecido (https://alura-site-scraping.herokuapp.com/index.php). No entanto, o meu código não deu certo. Estou tentando encontrar o erro, mas não consigo.
O código que usei foi esse:
# Importando bibliotecas
from urllib.request import urlopen, urlretrieve
from bs4 import BeautifulSoup
import pandas as pd
# Declarando variável cards
cards = []
## Obtendo o HTML e o total de páginas
response = urlopen('https://alura-site-scraping.herokuapp.com/index.php')
html = response.read().decode('utf-8')
soup = BeautifulSoup(html, 'html.parser')
pages = int(soup.find('span', class_="info-pages").get_text().split()[-1])
## Iterando por todas as páginas do site
for i in range(pages):
## Obtendo o HTML
response = urlopen('https://alura-site-scraping.herokuapp.com/index.php?page=' + str(i + 1))
html = response.read().decode('utf-8')
soup = BeautifulSoup(html, 'html.parser')
# Obtendo as TAGs de interesse
anuncios = soup.find('div', {"id": "container-cards"}).findAll('div', class_="card")
# Coletando as informações dos CARDS
for anuncio in anuncios:
card = {}
# Valor
card['value'] = anuncio.find('p', {'class': 'txt-value'}).getText()
# Informações
infos = anuncio.find('div', {'class': 'body-card'}).findAll('p')
for info in infos:
card[info.get('class')[0].split('-')[-1]] = info.get_text()
# Acessórios
items = anuncio.find('div', {'class': 'body-card'}).ul.findAll('li')
items.pop()
acessorios = []
for item in items:
acessorios.append(item.get_text().replace('► ', ''))
card['items'] = acessorios
# Adicionando resultado a lista cards
cards.append(card)
# Imagens
image = anuncio.find('div', {'class': 'image-card'}).img
urlretrieve(image.get('src'), './output/img/' + image.get('src').split('/')[-1])
# Criando um DataFrame com os resultados
dataset = pd.DataFrame(cards)
dataset.to_csv('./output/data/dataset.csv', sep=';', index = False, encoding = 'utf-8-sig')
dataset