Boa noite, conforme pedido no exercício, cheguei a mesma conclusão com uma forma um pouco diferente:
dados = alunos.groupby('Sexo')
for i, j in dados:
print('Sexo {} a média é {}'.format(i, round(j['Notas'].mean(), 2)))
Você está vendo a versão anterior da nova experiência da Alura que estamos preparando para você. Em breve, ela ganha uma identidade visual novinha totalmente pensada em potencializar seus estudos!

Boa noite, conforme pedido no exercício, cheguei a mesma conclusão com uma forma um pouco diferente:
dados = alunos.groupby('Sexo')
for i, j in dados:
print('Sexo {} a média é {}'.format(i, round(j['Notas'].mean(), 2)))


Oii Danival, como você está?
Existem várias formas de resolução e fico feliz que você tenha encontrado uma diferente da que foi proposta e obrigada por compartilhar essa forma conosco. Não há problemas quanto a resolver de forma diferente, o único ponto de atenção, é que o exercício pede para criarmos um novo dataFrame com as médias e partindo da forma como você fez, uma maneira de fazermos isso é salvarmos o resultado em uma lista de dicionários e após isso, passarmos o valor para o dataFrame. Veja como fica em código:
dados = alunos.groupby('Sexo')
valores = []
for i, j in dados:
valores.append({
"Sexo": i,
"Nota Média": round(j['Notas'].mean(), 2)
})
df = pd.DataFrame(valores)Resultado:

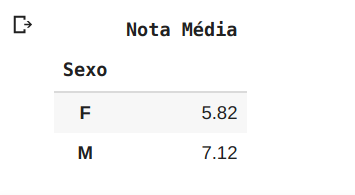
E caso queira utilizar o Sexo como índice do dataframe, basta utilizarmos a função set_index, como mostro abaixo:
df = pd.DataFrame(valores)
df.set_index("Sexo", inplace=True)Resultado:
Qualquer dúvida fico à disposição.
Grande abraço!