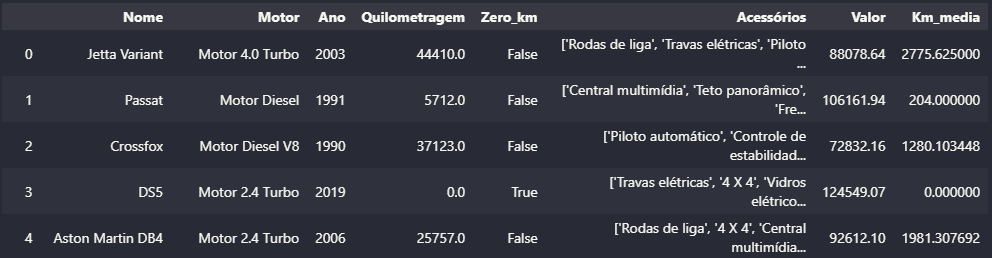
Seguindo o exemplo proposto em aula, também tive o problema de gerar duas colunas.
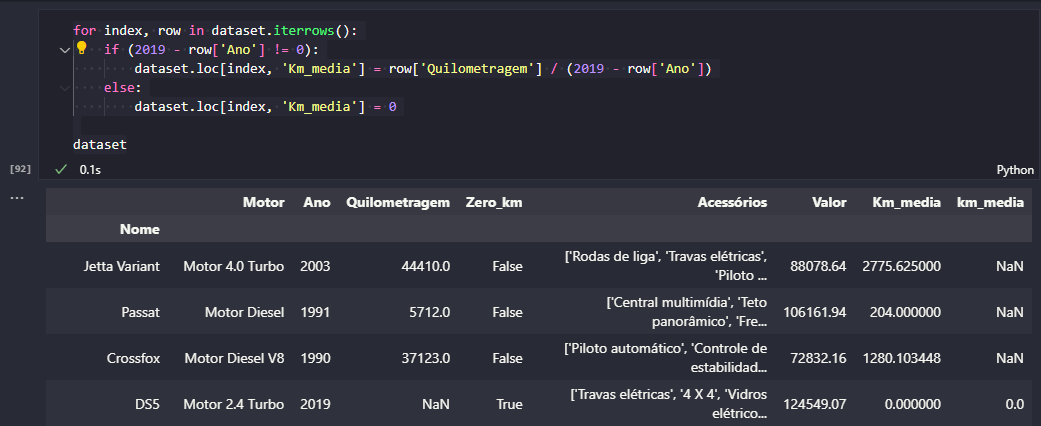
Isso se dá devido a linhas na coluna Quilometragem que está com o valor NaN.
Conforme a próxima aula eu fiz o seguinte:
dataset = pd.read_csv('data\db.csv', sep = ';')
dataset.fillna(0, inplace = True)
dataset.info()
Utilizando o dataset.info() gerou a informação que todas as linhas estão preenchidas:
<class 'pandas.core.frame.DataFrame'>
Index: 258 entries, Jetta Variant to Macan
Data columns (total 8 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Motor 258 non-null object
1 Ano 258 non-null int64
2 Quilometragem 197 non-null float64
3 Zero_km 258 non-null bool
4 Acessórios 258 non-null object
5 Valor 258 non-null float64
6 Km_media 258 non-null float64
7 km_media 61 non-null float64
dtypes: bool(1), float64(4), int64(1), object(2)
memory usage: 24.5+ KB
for index, row in dataset.iterrows():
if (2019 - row['Ano'] != 0):
dataset.loc[index, 'Km_media'] = row['Quilometragem'] / (2019 - row['Ano'])
else:
dataset.loc[index, 'Km_media'] = 0
dataset