
Olá, para aqueles que estão utilizando uma versão mais atual do pandas (versão 2.2.2 no meu caso) aqui está uma correção que funcionou comigo para deixar o último DataFrame igual ao elaborado em aula pelo professor. (CÓDIGO PARA COPIAR NO FINAL DO POST)
Versão do professor em aula:
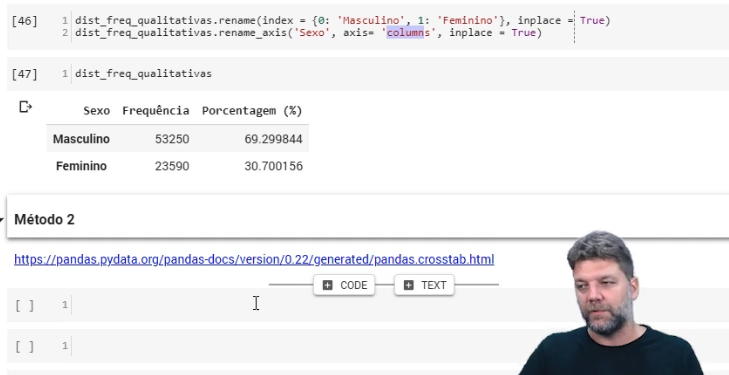
Como ficou o meu usando o mesmo código:
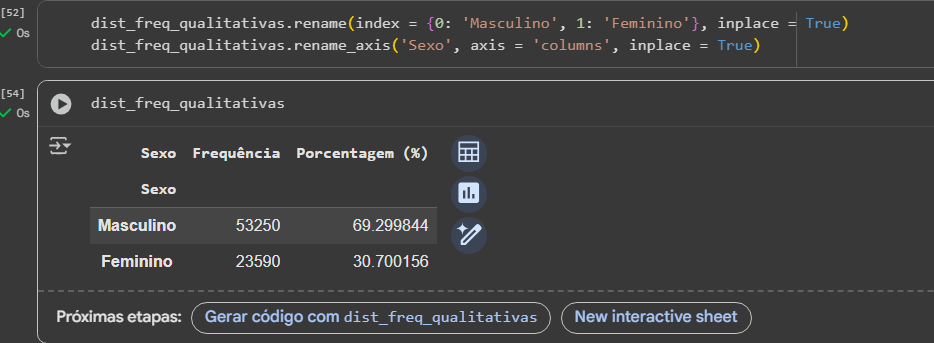
Como podem ver o titulo de coluna "Sexo" fica aparecendo duas vezes, para resolver isto utilizei dos seguintes passos:
1 - Copiar o código de criação do DataFrame feito anteriormente, para o mesmo bloco de código (isto é apenas para evitar erros de geração de novas colunas duplicadas que estavam acontecendo comigo com o código em um bloco separado)
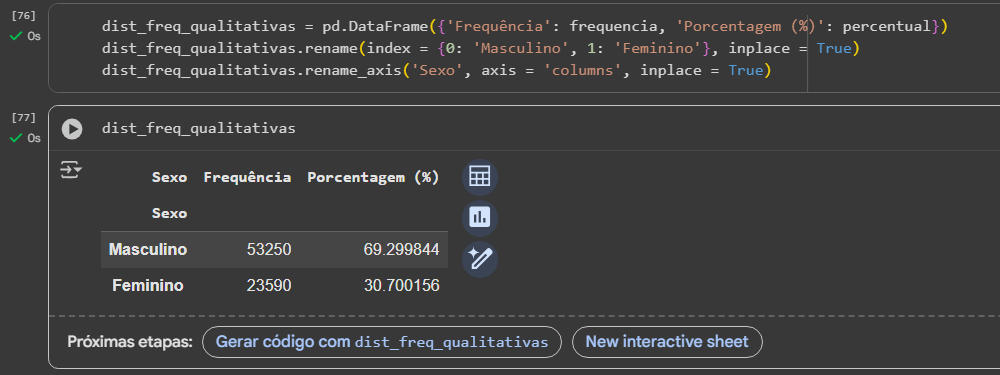
2 - Exclusão do código "rename_axis" para um reset do index, de modo que o nome de coluna "Sexo" apareça na mesma posição que "Frequência" e "Porcentagem (%)" sem estar duplicado
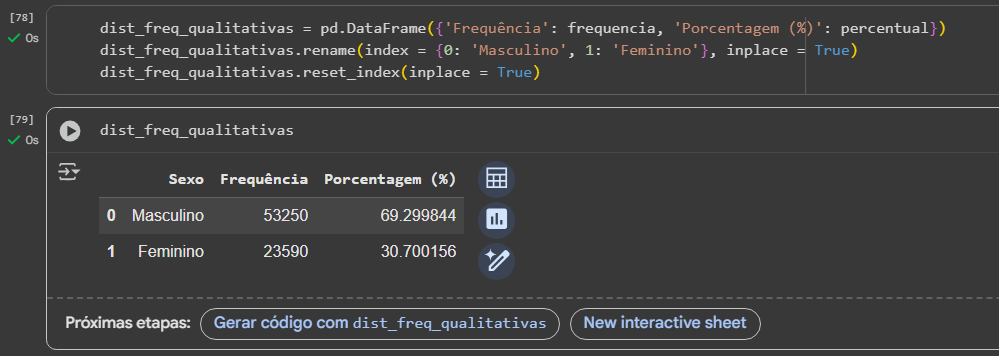
3 - Criação de uma lista vazia do tamanho do DataFrame para substituir os números do index (0 e 1) que apareceram ao lado de "Masculino" e "Feminino"
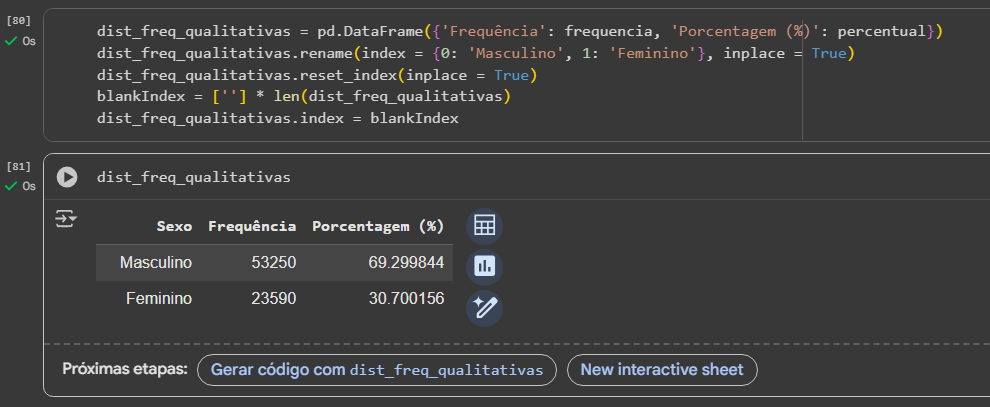
Essa foi a solução que encontrei para arrumar este problema na geração do DataFrame durante a aula afim de deixar o mais parecido com o resultado obtido pelo professor, como mostrado na primeira imagem do post. Espero ter explicado bem cada uma das etapas e caso alguém possua algum outro meio para solucionar este problema ou algo a acrescentar, sinta-se à vontade para compartilhar!
Segue abaixo o código para facilitar a correção:
dist_freq_qualitativas = pd.DataFrame({'Frequência': frequencia, 'Porcentagem (%)': percentual})
dist_freq_qualitativas.rename(index = {0: 'Masculino', 1: 'Feminino'}, inplace = True)
dist_freq_qualitativas.reset_index(inplace = True)
blankIndex = [''] * len(dist_freq_qualitativas)
dist_freq_qualitativas.index = blankIndex

