
1 - Importar bibliotecas a ser utilizadas: seabor, pandas.
import seaborn as sns #import libreria seaborn
import pandas as pd #trae libreria pandas
2 - Importar o arquivo.
tmdb = pd.read_csv("tmdb_5000_movies.csv")
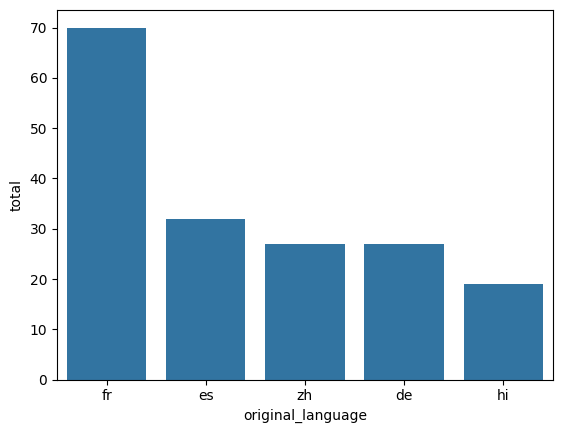
3 - Criar dataframe con os dados a ser trabalhados - total de filmes (count) em cada lingua (original_language) excluindo ingles. Contar total de filmes por linguas diferentes a ingles e colocar o t'itulo das colunas do dataframe:
total_por_lingua_de_outros_filmes = tmdb.query("original_language != 'en'").original_language.value_counts().to_frame().reset_index() #conta total de dados agrupados por 'original_language' sem ingles, conta o total, reseta indice.
total_por_lingua_de_outros_filmes.columns = ["original_language","total"] #coloca t'itulo das colunas
total_por_lingua_de_outros_filmes.head() #mostra o dataframe criado trazendo os 5 primeros datos.
original_language total
0 fr 70
1 es 32
2 zh 27
3 de 27
4 hi 19
4 - Plotar os dados Fazer grafico de barra - que facilita a leitura do mesmo.
sns.barplot(x="original_language",y="total",data = total_por_lingua_de_outros_filmes.head()) #grafico sobre os 5 primeiro valores
original_langue total - first 5 only.


