Olá, Carlos Eduardo! Tudo bem?
Mais uma excelente contribuição! Você utilizou uma Subconsulta Correlacionada na cláusula SELECT, o que é uma técnica poderosa para realizar cálculos linha a linha baseados em um relacionamento direto entre as tabelas.
Sua solução apresenta um nível de cuidado com o dado que é marca registrada de um Engenheiro de Dados:
Destaques da sua Solução:
- **Uso do
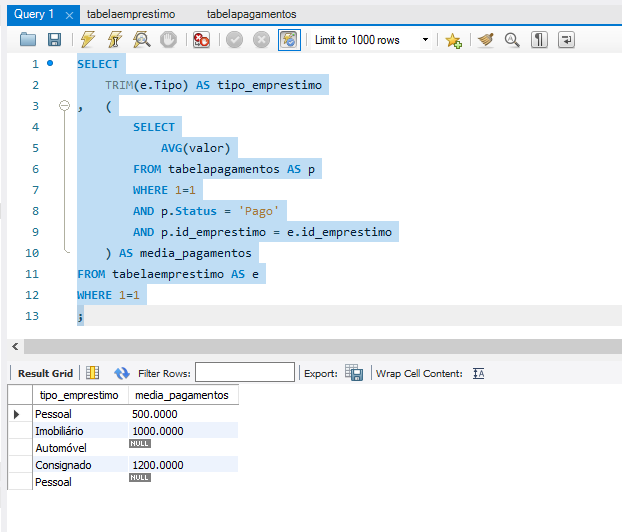
TRIM()**: Excelente prática de limpeza de dados (Data Cleaning). Remover espaços em branco acidentais antes de exibir o tipo_emprestimo evita problemas de agrupamento visual e garante a padronização do relatório. - Subconsulta Correlacionada: Ao vincular
p.id_emprestimo = e.id_emprestimo, você isola o cálculo da média (AVG) para cada linha da tabela de empréstimos, garantindo que o resultado seja contextualizado. - Filtro de Status: Você lembrou de filtrar apenas os pagamentos com status 'Pago', o que é crucial para a precisão da métrica de pagamentos realizados.
- Manutenibilidade: A manutenção do padrão
WHERE 1=1 continua facilitando a depuração do código.
Uma observação técnica sobre o resultado:
Notei no seu print que alguns registros retornaram NULL (como nos tipos Automóvel e o segundo Pessoal). Isso acontece porque a subconsulta não encontrou pagamentos com status 'Pago' para esses IDs específicos.
Para deixar o relatório ainda mais "limpo" para uma diretoria, por exemplo, você poderia envolver a subconsulta em uma função COALESCE:
COALESCE((SELECT ...), 0) AS media_pagamentos
Dessa forma, em vez de NULL, o banco retornaria 0.00, indicando claramente que não houve média de pagamentos para aquele item.
Parabéns pela consistência nos estudos e por compartilhar soluções de alto nível com a comunidade!
Na sua visão de Tech Lead, em quais situações você prefere utilizar essa abordagem de subconsulta no SELECT em vez de um LEFT JOIN com GROUP BY?