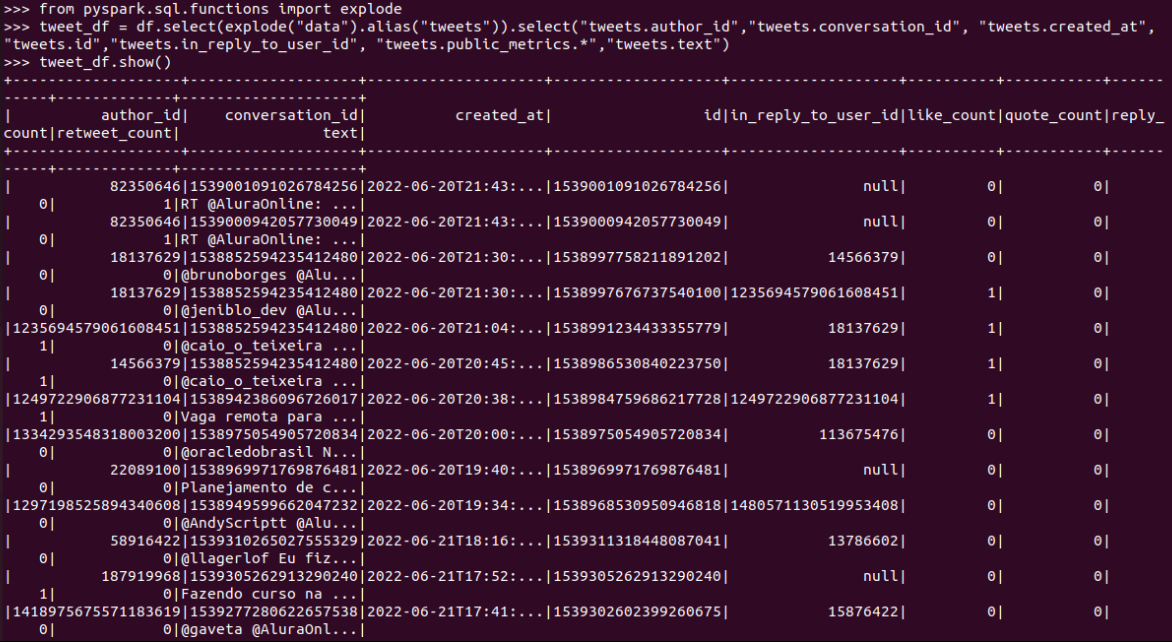
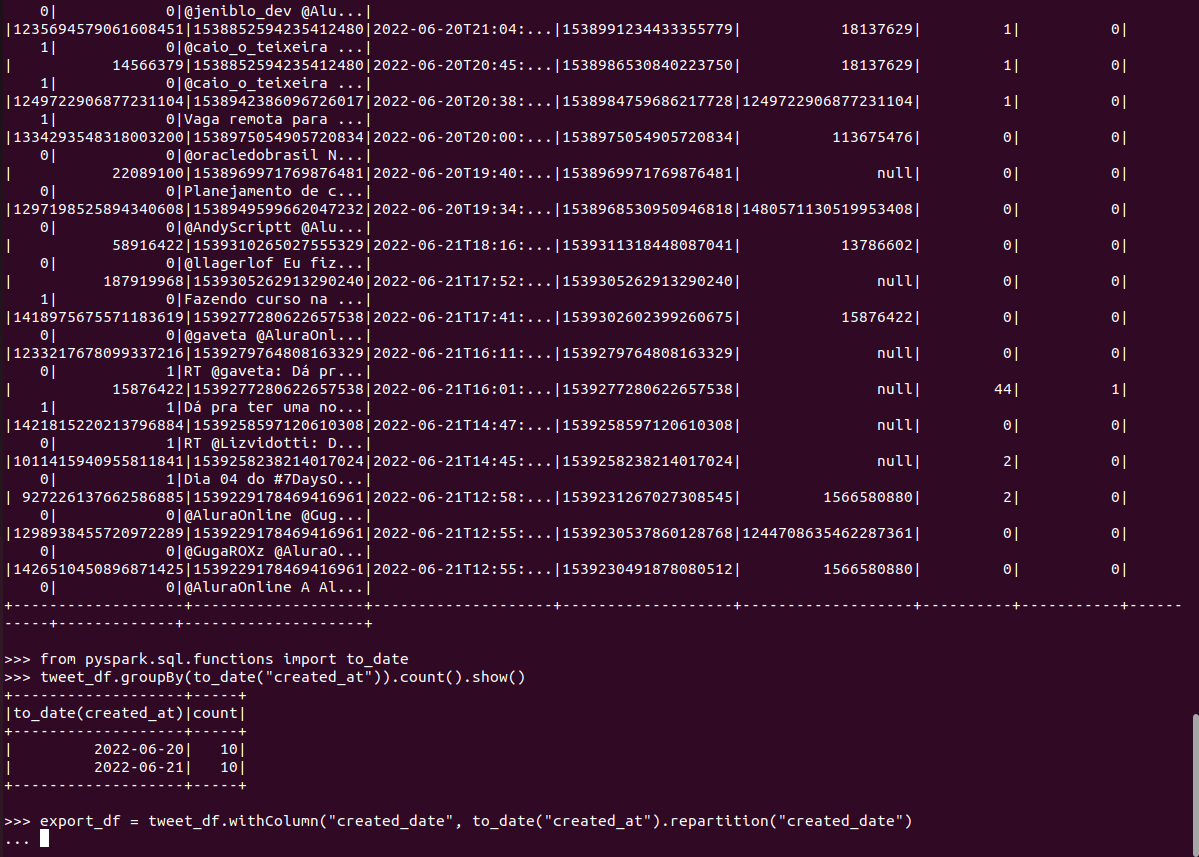
Ao realizar o groupby por created_at, está buscando a data do arquivo e não o campo de data do dataframe. Então ele não faz a partição pelas data dos dados, pois considera apenas uma data só. Sabem o que pode ser?
Você está vendo a versão anterior da nova experiência da Alura que estamos preparando para você. Em breve, ela ganha uma identidade visual novinha totalmente pensada em potencializar seus estudos!

Ao realizar o groupby por created_at, está buscando a data do arquivo e não o campo de data do dataframe. Então ele não faz a partição pelas data dos dados, pois considera apenas uma data só. Sabem o que pode ser?
