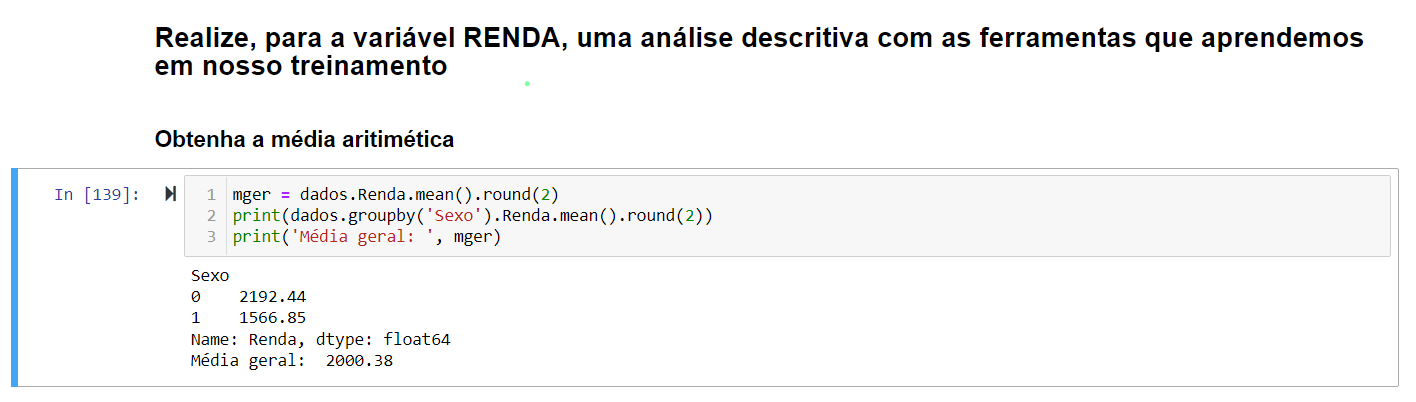
Organizando o print. Não sei como separar o groupby, formatando a linha. Eu gostaria de ver as médias organizadas assim: Media Geral Média Masculino Média Feminino
No dataset, eu gostaria de trocar 0 por M e 1 por F. A mesma coisa para as UFs, que estão com números. Por exemplo, a UF 11 é SP. Como fazer?
Essa prática, de trocar o conteúdo do dataset, para deixá-lo mais "mneumônico", ou fácil de entender, é uma boa prática? Ou tem alguma desvantagem que desconheço?
Os outliers atrapalham demais a análise. Como estamos fazendo exercício, apenas, eu quero excluir os outliers de renda. Como fazer? Usa-se drop, para os valores máximos?