Você está vendo a versão anterior da nova experiência da Alura que estamos preparando para você. Em breve, ela ganha uma identidade visual novinha totalmente pensada em potencializar seus estudos!



Olá, William. Como vai?
O seu projeto prático ficou muito bem estruturado e demonstra uma excelente compreensão dos conceitos de normalização de dados aplicados na prática! É muito interessante ver você utilizando a biblioteca Pandas em Python para realizar a decomposição de tabelas de forma puramente relacional.
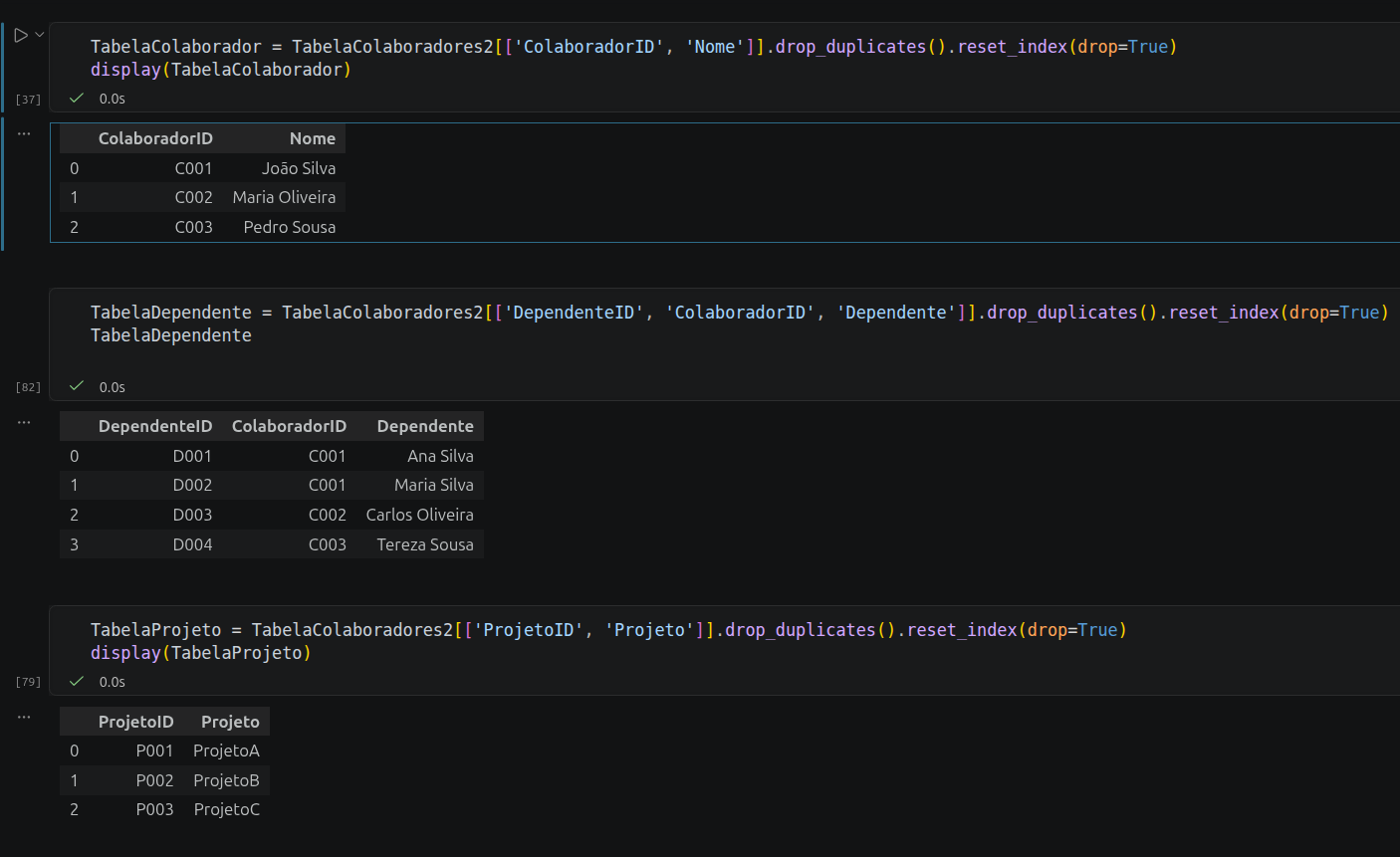
A sua modelagem seguiu com precisão os princípios de eliminação de redundâncias e prevenção de anomalias de inserção, atualização e exclusão de dados. Gostaria de destacar a coerência técnica das suas divisões:
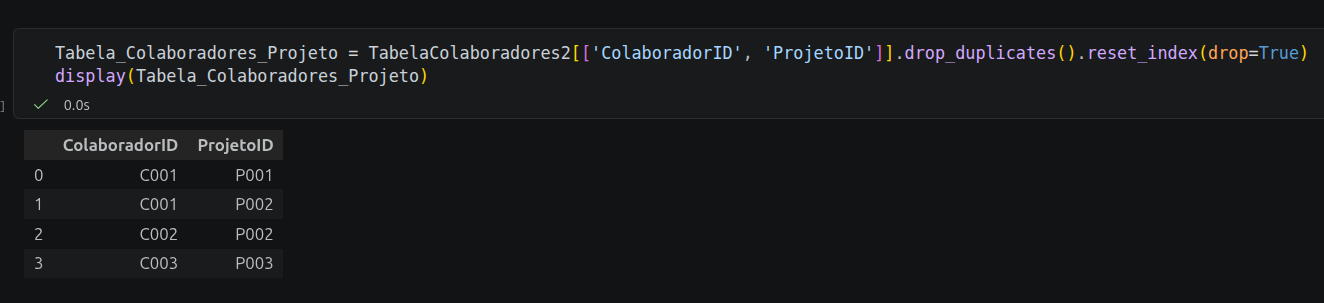
ColaboradorID como a chave primária e o Nome como o único atributo funcionalmente dependente dele.DependenteID para identificação exclusiva, enquanto o ColaboradorID atua como chave estrangeira, ligando o dependente ao seu respectivo responsável sem a necessidade de repetir os dados do colaborador.ProjetoID e o nome do Projeto.ColaboradorID e ProjetoID), o que garante a consistência referencial e economiza espaço físico de armazenamento.Como contribuição prática para os seus estudos e para conectar esse processo de manipulação de dados em Pandas diretamente com o universo de Bancos de Dados Relacionais e consultas SQL, gostaria de deixar uma sugestão:
Sempre que você finalizar a modelagem e a normalização dos seus DataFrames no Jupyter Notebook ou VS Code, você pode exportar essas tabelas diretamente para um banco de dados relacional local (como o SQLite, que é leve e não exige instalação de servidores) para começar a testar as suas queries de consulta utilizando cláusulas JOIN.
Você pode fazer isso facilmente com poucas linhas de código utilizando a biblioteca nativa sqlite3 do Python e o método .to_sql() do Pandas:
import sqlite3
# Conecta a um banco de dados SQLite local (se não existir, o arquivo será criado)
conexao = sqlite3.connect('empresa_normalizada.db')
# Exporta os DataFrames do Pandas como tabelas do banco de dados relacional
TabelaColaborador.to_sql('colaboradores', conexao, if_exists='replace', index=False)
TabelaDependente.to_sql('dependentes', conexao, if_exists='replace', index=False)
TabelaProjeto.to_sql('projetos', conexao, if_exists='replace', index=False)
Tabela_Colaboradores_Projeto.to_sql('colaboradores_projetos', conexao, if_exists='replace', index=False)
print("Banco de dados relacional criado e tabelas importadas com sucesso!")
Após rodar esse bloco, você terá um arquivo de banco de dados relacional real em sua máquina. Você poderá utilizá-lo para praticar a escrita de comandos SQL e realizar junções para validar se a sua decomposição ocorreu sem perda de informações (lossless join decomposition).
Parabéns pela qualidade técnica e pela excelente organização do código apresentado!
Espero que possa ter lhe ajudado!