Olá, Izabel! Tudo bem?
Parabéns pela execução do projeto! Você utilizou uma das técnicas mais eficientes do SQL para manipulação de grandes volumes de dados: a inserção baseada em uma consulta, também conhecida como INSERT INTO ... SELECT.
Aqui estão os pontos de destaque da sua atividade:
1. Migração de Dados Estruturada
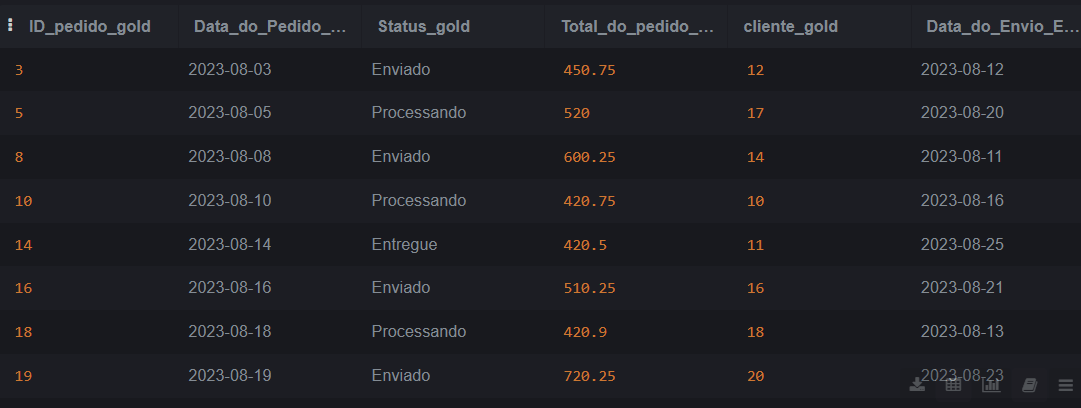
O seu código reflete um cenário muito comum no dia a dia de um Analista de Dados: a criação de tabelas de "elite" ou "ouro" (camada Gold).
- Filtro de Negócio: Ao definir
where total_do_pedido >= 400, você transformou uma massa de dados bruta em informação estratégica, isolando apenas os pedidos de alto valor.
2. Mapeamento de Colunas
Notei que você teve o cuidado de listar explicitamente as colunas da tabelapedidosgold.
- Por que isso é bom? Mesmo que os nomes das colunas de origem (
id, status, etc.) sejam diferentes dos nomes de destino (ID_pedido_gold, status_gold), o SQL consegue fazer o "de-para" corretamente baseando-se na ordem que você definiu. Isso traz muita segurança ao código.
Entendendo o Fluxo Visualmente
O que você executou pode ser visualizado como um filtro que "pesca" registros de uma tabela maior e os deposita em uma tabela mais específica:
Dica para Evolução
Como você está trabalhando com tabelas que representam categorias (como a Gold), uma boa prática é garantir que você não insira o mesmo pedido duas vezes se rodar o script novamente.
Para isso, no futuro, você pode adicionar uma pequena verificação no final do seu SELECT:
-- Exemplo de como evitar duplicatas
FROM tabelapedidos
WHERE total_do_pedido >= 400
AND id NOT IN (SELECT ID_pedido_gold FROM tabelapedidosgold);
Sua entrega demonstra que você compreendeu perfeitamente como automatizar a alimentação de tabelas usando critérios lógicos. Continue explorando essas instruções, elas são fundamentais para construir processos de dados robustos!
O que você achou dessa forma de inserir dados em comparação ao INSERT INTO ... VALUES manual?