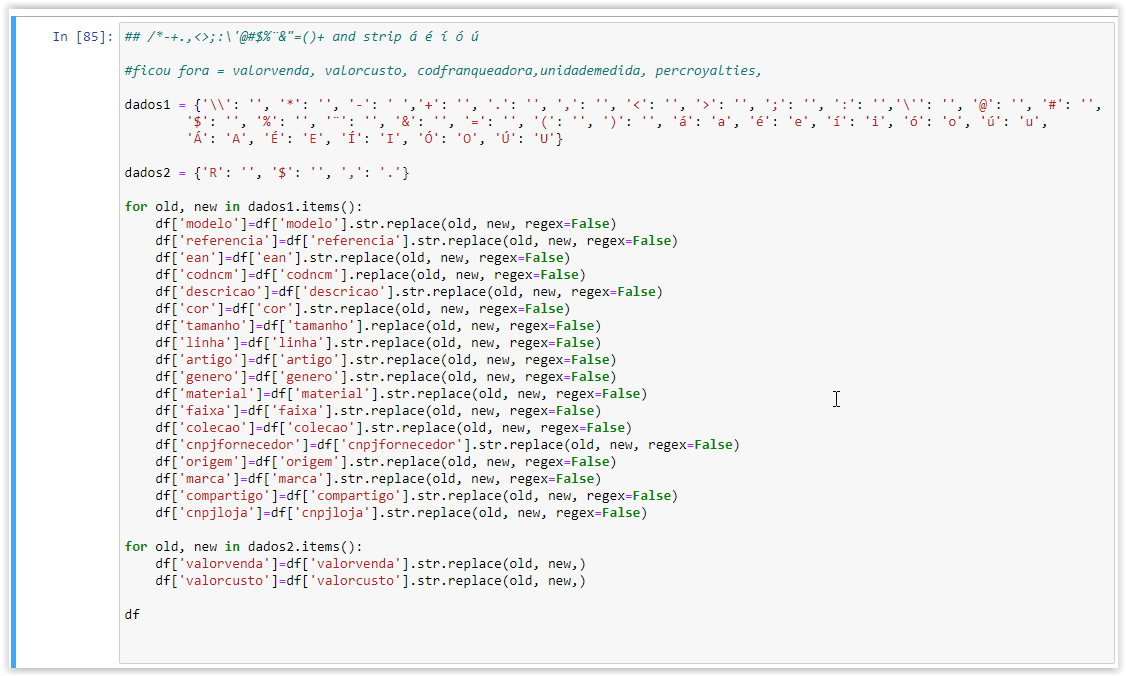
Como eu poderia diminuir todas essas linhas com as colunas do meu arquivo csv?
Eu tentei criar um grupo colunas={1,2,3,4,} mas não consegui encaixar ele no replace.
Você está vendo a versão anterior da nova experiência da Alura que estamos preparando para você. Em breve, ela ganha uma identidade visual novinha totalmente pensada em potencializar seus estudos!

Como eu poderia diminuir todas essas linhas com as colunas do meu arquivo csv?
Eu tentei criar um grupo colunas={1,2,3,4,} mas não consegui encaixar ele no replace.


Oi Maigui! Tudo bem com você?
Se a presença ou não do .str nos comandos .str.replace(old,new,regex=False) e .replace(old,new,regex=False) interfere muito no resultado das colunas, uma opção é você estruturar uma variável iterável com os nomes das colunas que mantenham o mesmo padrão de replace. Por exemplo, unir em uma lista com as colunas que devem ser acessadas ao utilizar .str.replace(old,new,regex=False) e .replace(old,new,regex=False) e depois acessar os dados dessas colunas com um laço for:
lista_str = ['modelo','referencia','ean','descricao','cor','linha','artigo','genero','material','faixa','colecao','cnpjfornecedor','origem','marca','compartigo','cnpjloja']
lista_sem_str = ['codncm','tamanho']
for old, new in dados1.items():
for coluna in lista_str:
df[coluna] = df[coluna].str.replace(old,new,regex=False)
for coluna in lista_sem_str:
df[coluna] = df[coluna].replace(old,new,regex=False)Eu espero que dessa forma fique melhor a utilização. Se surgir outra dúvida estarei à disposição.

Muito obrigado