Olá, Aristóteles! Como vai?
Excelente publicação! O seu post traz um passo a passo impecável e muito bem documentado da fase que mais consome o tempo de um Cientista de Dados no dia a dia: a Análise Exploratória de Dados (EDA).
Seu código seguiu perfeitamente o fluxo recomendado para entender o comportamento de um conjunto de dados novo. Você importou os dados, conferiu o tamanho da base com o .shape, checou os tipos de dados com o .info() e o .dtypes, isolou variáveis e fechou com o resumo estatístico do .describe().
Para contribuir com o seu tópico e ajudar os colegas que estão analisando esses mesmos resultados, vamos fazer uma leitura crítica dos dados que apareceram nos seus prints? O Pandas nos deu pistas valiosíssimas sobre a qualidade dessa base de alunos.
Interpretando os Sinais do .info() e do .describe()
Olhando atentamente para as imagens do seu notebook, existem dois pontos analíticos fundamentais que você já consegue extrair para iniciar o tratamento desses dados:
1. O Alerta dos Dados Nulos (NaN)
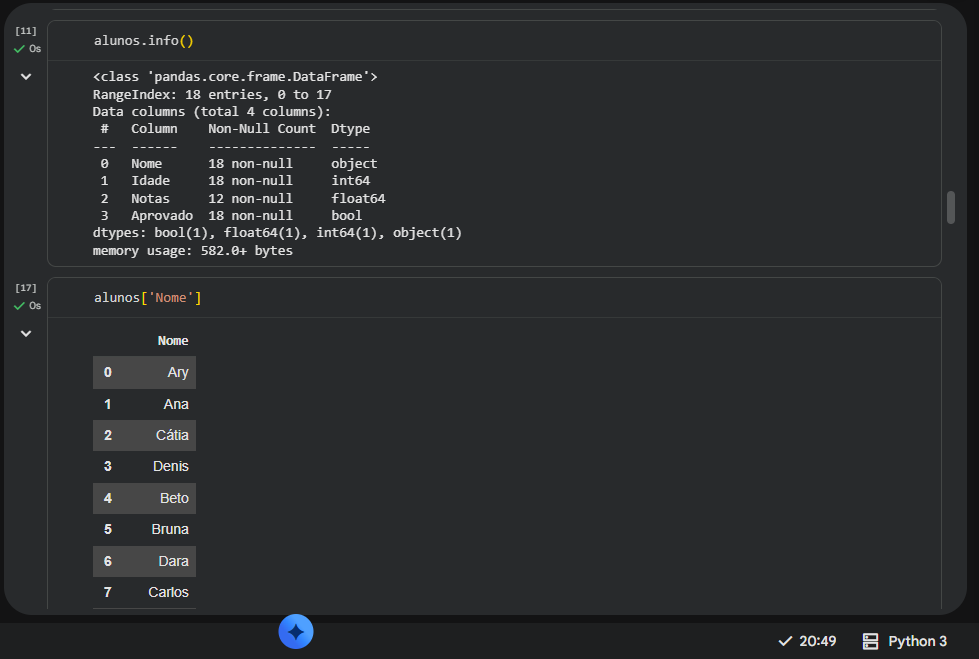
No print do seu comando alunos.info(), o Pandas indicou que a base possui 18 entradas (linhas).
- As colunas
Nome, Idade e Aprovado mostram 18 non-null, ou seja, estão totalmente preenchidas. - No entanto, a coluna
Notas exibe apenas 12 non-null.
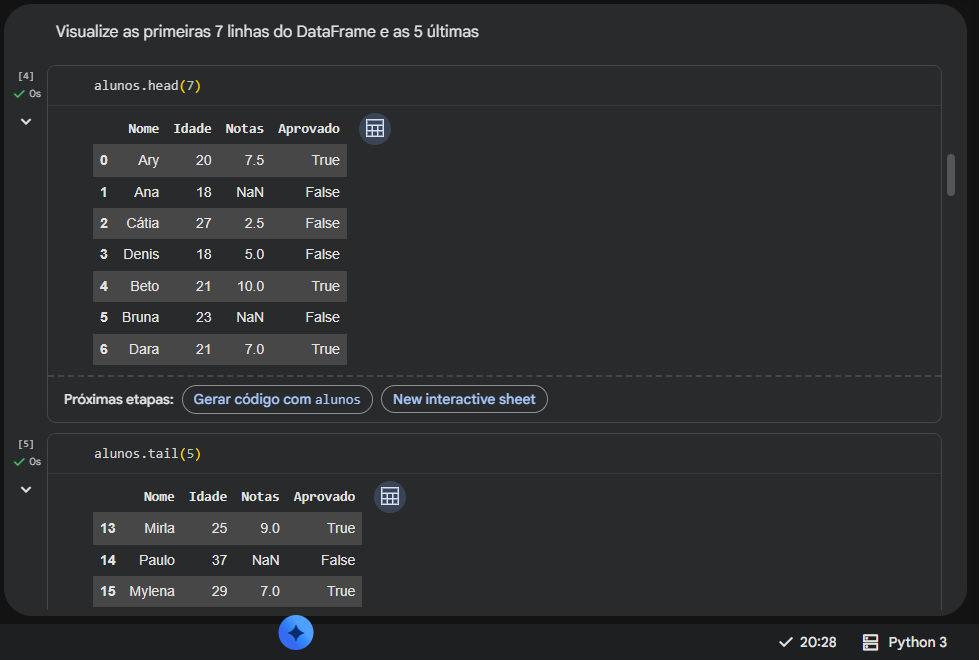
Isso significa que existem 6 alunos com notas faltando (valores nulos) no seu dataset. No print do seu .head(7), já conseguimos ver a Ana (linha 1) e a Bruna (linha 5) com o valor NaN (Not a Number). Essa conferência visual bate exatamente com o seu print do .describe(), onde a contagem (count) para a coluna Idade é 18, mas para Notas é 12.
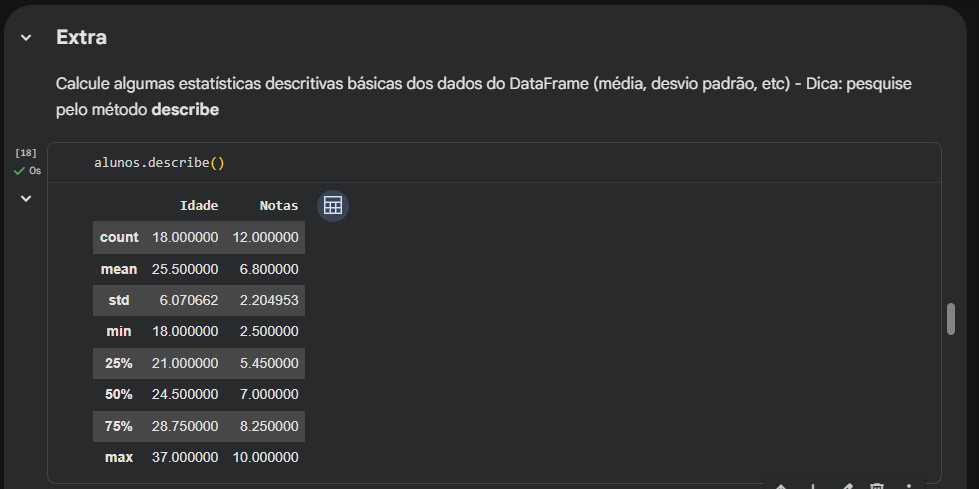
2. Decifrando o Resumo Estatístico (.describe())
O método .describe() é uma máquina de insights para entender o perfil da turma. Olhando para a coluna de Idade:
mean (Média): A idade média dos alunos é de 25.5 anos.min e max: O aluno mais novo tem 18 anos e o mais velho tem 37 anos.- Os Percentis (25%, 50%, 75%): Eles dividem os seus dados em quatro partes iguais. O percentil de 50% é a Mediana. Ela nos diz que exatamente metade da turma tem até 24.5 anos, e a outra metade tem mais que isso.
Uma Pequena Dica de Sintaxe para o seu Código
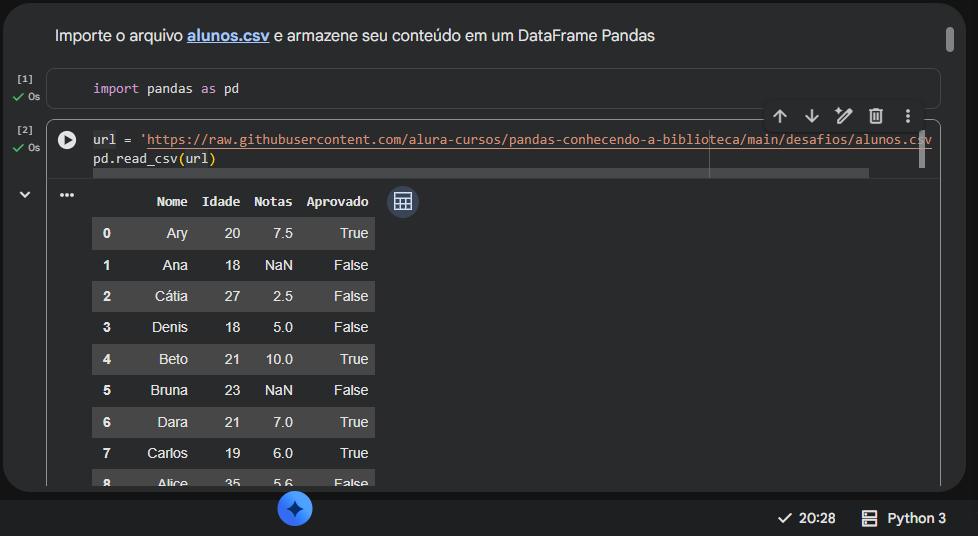
No seu texto, você documentou muito bem as linhas de importação:
url = 'https://raw.githubusercontent.com/alura-cursos/pandas-conhecendo-a-biblioteca/main/desafios/alunos.csv'
pd.read_csv(url)
Para que os comandos seguintes (como alunos.head(7) ou alunos.info()) funcionem nas células de baixo sem retornar um erro de NameError: name 'alunos' is not defined, lembre-se sempre de atribuir o resultado da leitura a uma variável.
Basta ajustar a sua célula inicial adicionando o sinal de igual para salvar o DataFrame na memória:
# Atribuindo o CSV à variável 'alunos'
alunos = pd.read_csv(url)
Parabéns pela organização visual do seu post e pelo progresso excelente na biblioteca Pandas. Você tem uma ótima didática para estruturar relatórios de dados!
Espero que possa ter lhe ajudado!