Olá Mariana,
Antes de mais nada, desculpe a demora na resposta. Estamos em um esforço para zerar as dúvidas do fórum.
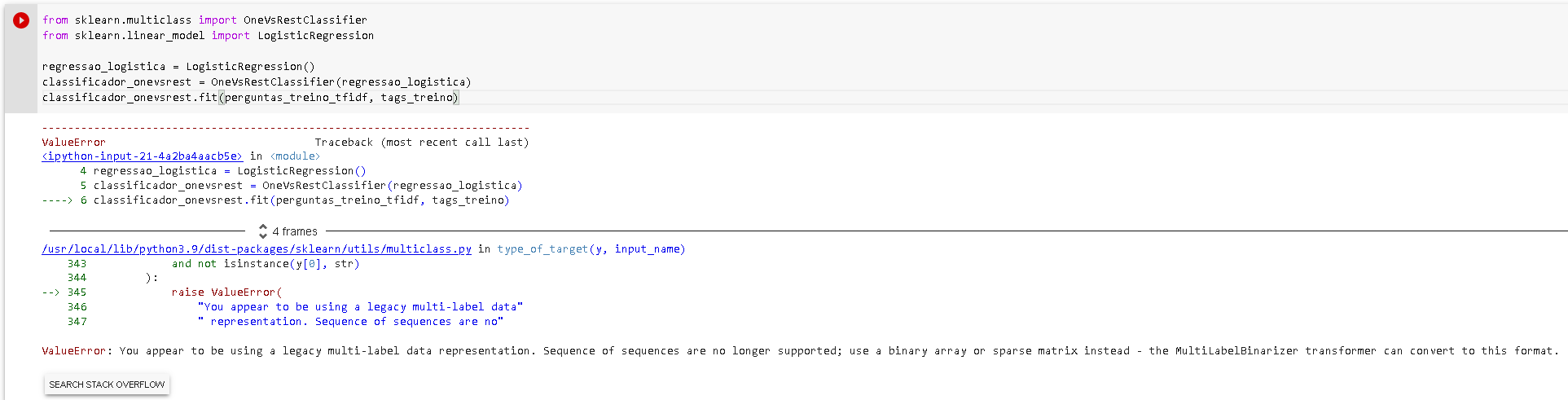
Você não precisa usar o MultiLabelBinarizer(). Basta seguir o que o Thiago fez nos vídeos seguintes, ele corrige esse problema que apareceu de intencional.
Se você aplicar essa sequência de código deve conseguir resolver essa primeira etapa. Mesmo assim, aconselho que continue para os próximos vídeos para entender as etapas envolvidas.
from sklearn.model_selection import train_test_split
perguntas_treino, perguntas_teste, tags_treino, tags_teste = train_test_split(perguntas['Perguntas'],lista_zip_tags,test_size=0.2,random_state=123)
from sklearn.feature_extraction.text import TfidfVectorizer
vetorizar = TfidfVectorizer(max_features=5000, max_df=0.85)
vetorizar.fit(perguntas['Perguntas'])
import numpy as np
tags_treino_array = np.asarray(list(tags_treino))
tags_teste_array = np.asarray(list(tags_teste))
perguntas_treino_tfidf = vetorizar.transform(perguntas_treino)
perguntas_teste_tfidf = vetorizar.transform(perguntas_teste)
from sklearn.multiclass import OneVsRestClassifier
from sklearn.linear_model import LogisticRegression
regressao_logistica = LogisticRegression(solver='lbfgs')
classificador_onevsrest = OneVsRestClassifier(estimator=regressao_logistica)
classificador_onevsrest.fit(perguntas_treino_tfidf,tags_treino_array)
classificador_onevsrest.score(perguntas_teste_tfidf,tags_teste_array)