
no caso quando você usa config_tesseract = '--tessdata-dir tessdata --psm 6'
texto = pytesseract.image_to_string(img, lang='por', config=config_tesseract)
print(texto) vc utilizaa ese codigo como se tivese feito em uma aula anterior mas vc não fez pode explicar isso por favor ?
ma parte de Undersampling vc copia e cola config_tesseract = '--tessdata-dir tessdata --psm 6'
texto = pytesseract.image_to_string(img, lang='por', config=config_tesseract)
print(texto) mas vc so fez texto = pytesseract.image_to_string(img)
print(texto) mas vc so fez texto = pytesseract.image_to_string(img)
print(texto) acho que flata explicarr isso?
para contextualizar o que falei olha essa imagen
antes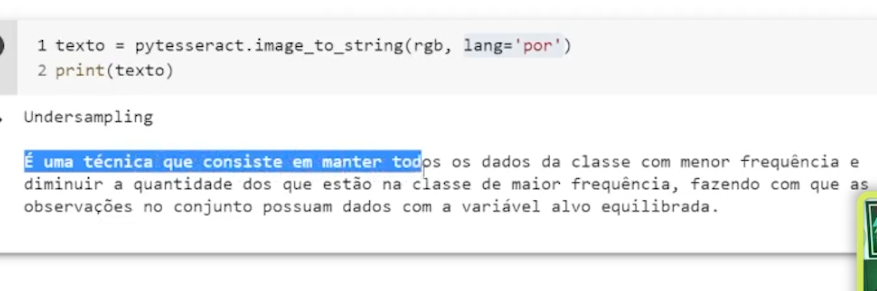
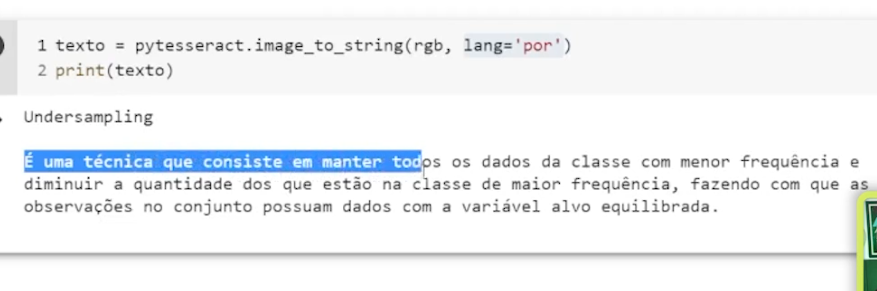
depois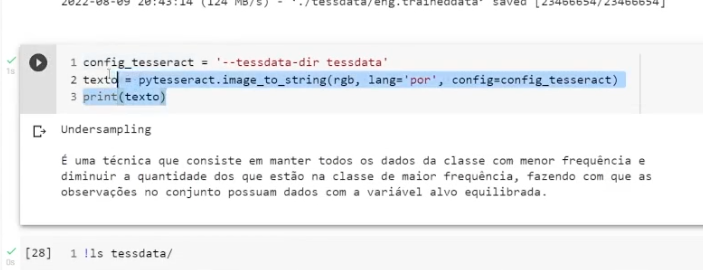
/home/miguel/Área de trabalho/Captura de tela de 2025-08-28 13-53-55.png

