
Estou tentando aplicar o conhecimento adquirido nesse curso para coletar alguns dados, nesse site, para um pesquisa do mestrado.
Eu preciso acessar os dados dessa tag table (quadrado amarelo), porém, quando procuro por soup.find('table'), nada é encontrado.
Também tentei procurar por soup.find('div', id="app") (quadrado verde), mas nada é encontrado.
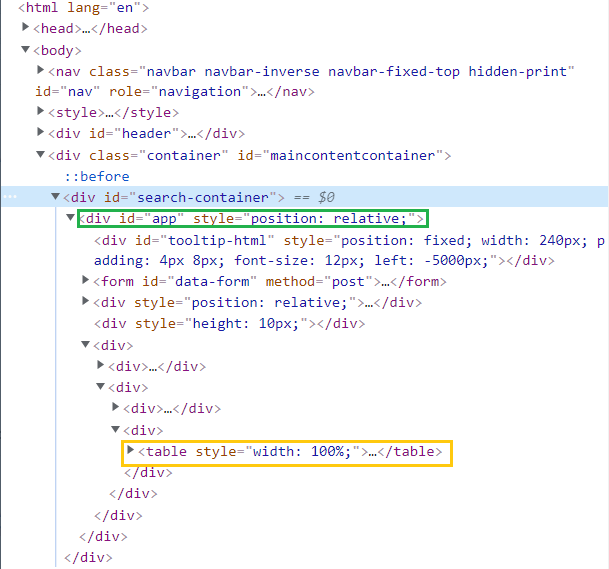
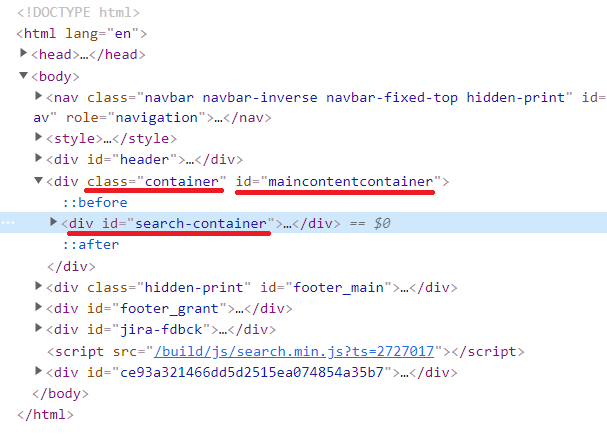
Se eu procurar por soup.find('div',{'class':"container", 'id':"maincontentcontainer"}), obtenho isso:
<div class="container" id="maincontentcontainer"><div id="search-container"></div></div>
E se eu procurar por soup.find('div',id="search-container"), obtenho apenas <div id="search-container"></div>, como se não existisse nada dentro do bloco
Eu notei que esse bloco <div id="search-container"></div> está entre esses termos::before e ::after. Eu suspeito que seja por causa disso que não consigo acessar os termos dentro do bloco <div id="search-container"></div>.
Se alguém puder dar qualquer ajuda , agradeço.
Esse é o código que usei:
from bs4 import BeautifulSoup
import pandas as pd
from urllib.request import Request, urlopen
response = urlopen(url)
html = response.read()
html = html.decode('utf-8')
html = " ".join(html.split()).replace('> <', '><')
soup = BeautifulSoup(html, 'html')
soup.find('div',{'class':"container", 'id':"maincontentcontainer"})
soup.find('div',id="search-container")
soup.find('div', id="app")
soup.find('div', id="app")soup.find('table')
