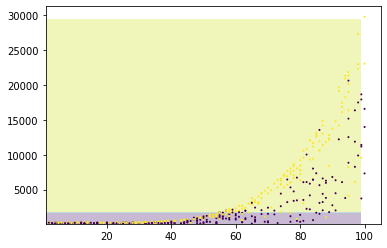
Mesmo depois de alterar de LinearSVC para SVC, o gráfico continua com o comprotamento Linear.
import pandas as pd
from sklearn.svm import LinearSVC, SVC
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
import numpy as np
!pip install seaborn==0.9.0
import seaborn as sns
import matplotlib.pyplot as plt
uri = "https://gist.githubusercontent.com/guilhermesilveira/1b7d5475863c15f484ac495bd70975cf/raw/16aff7a0aee67e7c100a2a48b676a2d2d142f646/projects.csv"
dados = pd.read_csv(uri)
dados.head()
renomear = {
'expected_hours' : 'horas_esperadas',
'price' : 'preco',
'unfinished' : 'nao_finalizado'
}
dados = dados.rename(columns = renomear)
dados.head()
change = {0:1, 1:0}
dados['finalizado'] = dados['nao_finalizado'].map(change)
dados_x = dados[['horas_esperadas','preco']]
dados_y = dados['finalizado']
#SEPARAR AMOSTRAS
seed = 10
np.random.seed(seed)
train_x, test_x, train_y, test_y = train_test_split(dados_x, dados_y, test_size = 0.25, stratify = dados_y)
print(f'Treinaremos com {train_y.shape[0]} elementos e testaremos com {test_y.shape[0]} elementos')
#criar modelo
modelo = SVC()
modelo.fit(train_x, train_y)
predict = modelo.predict(test_x)
acuracia = accuracy_score(test_y, predict)
print(f'A acurácia do modelo foi de {round(acuracia*100,2)}%')
x_min = test_x['horas_esperadas'].min()
x_max = test_x['horas_esperadas'].max()
y_min = test_x['preco'].min()
y_max = test_x['preco'].max()
print(x_min, x_max, y_min, y_max )
pixels = 100
eixo_x = np.arange(x_min, x_max, (x_max-x_min)/pixels)
eixo_y = np.arange(y_min, y_max, (y_max-y_min)/pixels)
xx, yy = np.meshgrid(eixo_x, eixo_y)
pontos = np.c_[xx.ravel(), yy.ravel()]
#usando o modelo
Z = modelo.predict(pontos)
Z = Z.reshape(xx.shape)
Z.shape
import matplotlib.pyplot as plt
plt.contourf(xx, yy, Z, alpha=0.30)
plt.scatter(test_x['horas_esperadas'], test_x['preco'], s=1, c=test_y)