Olá,
Estava analisando a proposta e o código utilizando para solucionar o problema. No meu ver o código utilizado é inefetivo para o problema, pois ao rodarmos o código :
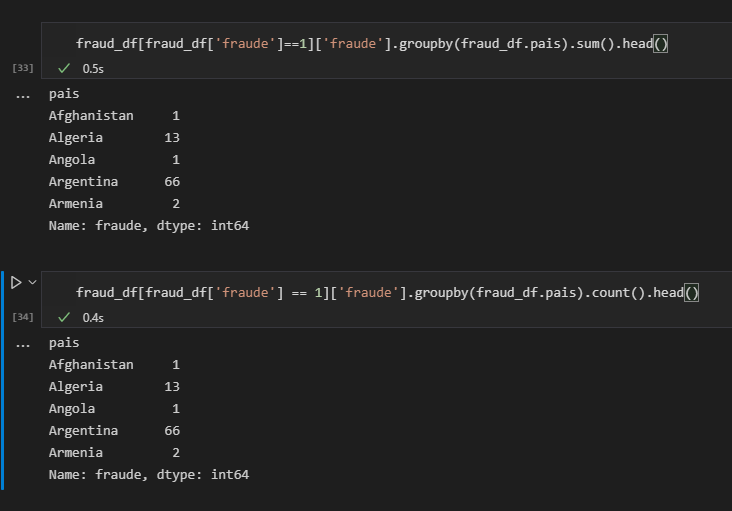
> sums_nf = fraud_df[fraud_df[“fraude”]==0 [“fraude”].groupby(fraud_df.pais).sum()
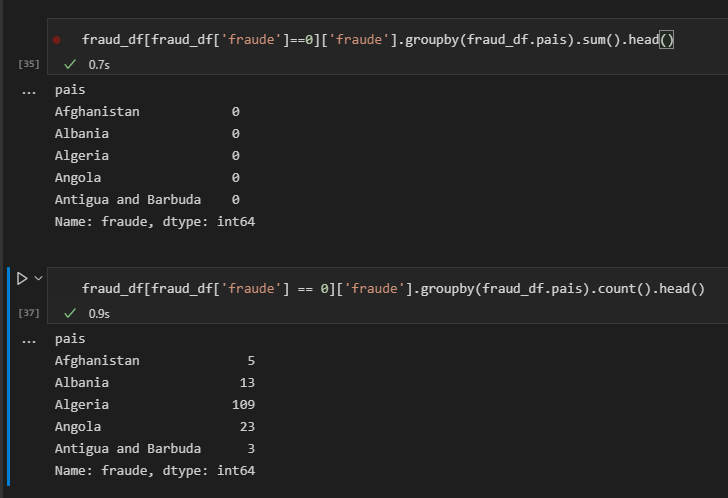
sums_nf = sums_nf.to_frame().reset_index()E verificarmos os retornos, todos os países recebem o atributo zero, ou seja, ao plotarmos o gráfico de barras para verificarmos quais os países que estão menos envolvidos em fraudes temos um lista gigante com todos os países que já realizaram compras, e não necessariamente não estão envolvidos com fraudes.
A solução por mim encontrada foi: Somar todas as transações não fraudulentas por país, excluir os países que tem fraude dessa lista. Assim teríamos uma lista de países que não possuem histórico de fraude e com possibilidades de campanhas de vendas.
Podem me ajudar com o código para realizar isso?
Eu consegui apenas contabilizar o total de transações não fraudulentas com o seguinte código:
>sums_nf = fraude_df[fraude_df['fraude'] == 0]['fraude'].groupby(fraude_df.pais).count()
sums_nf = sums_nf.to_frame().reset_index()