Isto me aparece quando eu tento rodar
Você está vendo a versão anterior da nova experiência da Alura que estamos preparando para você. Em breve, ela ganha uma identidade visual novinha totalmente pensada em potencializar seus estudos!

Isto me aparece quando eu tento rodar


Oi, Lúcio! Tudo bem contigo?
Existem alguns possíveis motivos para que tenha acontecido o erro que você relatou, então vou citar os erros e soluções para eles e caso nenhum deles seja a solução correta para seu caso, por favor, não hesite em informar. Vamos aos erros.
1° Possível erro: Seu notebook do colab pode estar a muito tempo desconectado e para isso seria necessário solicitar que ele retorne a conexão para o ambiente funcionar corretamente.
2° Possível erro: Pode ser que nem todas as células estejam executadas de forma que algum dado pode estar faltando.
Para ambos os erros mencionados, basta reiniciar o kernel e executar todo o código, conforme imagem abaixo, que resolverá. Para reiniciar o kernel do seu notebook, vá até a aba “ambiente de execução”, no seu google colab, e dentro dessa aba clica em "reiniciar e executar tudo”.

Espero ter ajudado, mas caso ainda persista seu problema, você pode colocar seu código aqui, para que seja possível testá-lo.
Qualquer dúvida estou sempre à disposição.
Reiniciei e executei tudo e persistiu no erro, irei deixar o meu código abaixo aqui, eu tentei fazer o mesmo no jupyter e deu o mesmo erro, e sem isso eu não consigo dar continuidade nos estudos de machine learning, se conseguir descobrir o problema só mandar msg aqui
import pandas as pd
dados = pd.read_csv('https://gist.githubusercontent.com/guilhermesilveira/1b7d5475863c15f484ac495bd70975cf/raw/16aff7a0aee67e7c100a2a48b676a2d2d142f646/projects.csv')
dados.head(10)
mapa = {
'unfinished':'incompletos',
'expected_hours':'horas_esperadas',
'price':'preco',
}
dados.rename(columns = mapa, inplace = True)
troca = {
0 : 1,
1 : 0,
}
dados['completos'] = dados.incompletos.map(troca)
dados
import seaborn as sns
sns.scatterplot(x="horas_esperadas", y="preco",hue='completos', data=dados)
sns.relplot(x="horas_esperadas", y="preco", hue="completos", col="completos", data=dados)
x = [['horas_esperadas', 'preco']]
y = [['finalizado']]
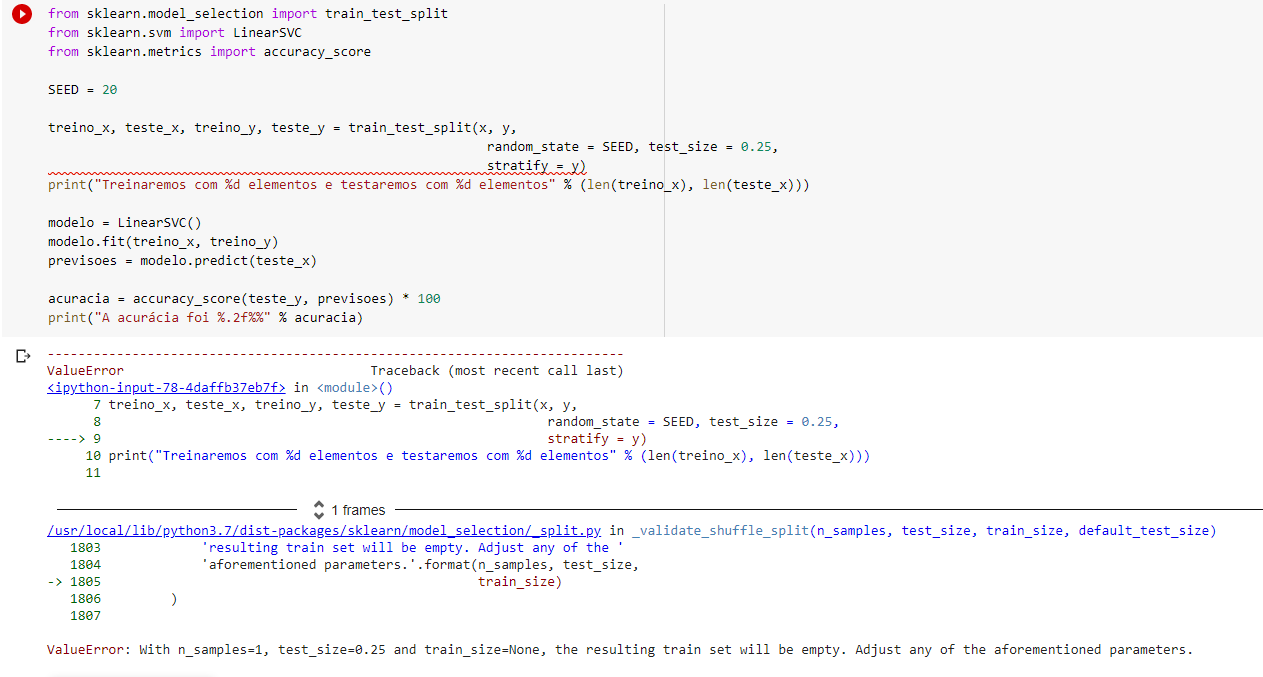
from sklearn.model_selection import train_test_split
from sklearn.svm import LinearSVC
from sklearn.metrics import accuracy_score
SEED = 20
treino_x, teste_x, treino_y, teste_y = train_test_split(x, y,
random_state = SEED, test_size = 0.25,
stratify = y)
print("Treinaremos com %d elementos e testaremos com %d elementos" % (len(treino_x), len(teste_x)))
modelo = LinearSVC()
modelo.fit(treino_x, treino_y)
previsoes = modelo.predict(teste_x)
acuracia = accuracy_score(teste_y, previsoes) * 100
print("A acurácia foi %.2f%%" % acuracia)
Oi, Lúcio! Tudo tranquilo ?
O erro está acontecendo porque você está passando para o train_test_split() duas listas, x e y, uma com dois elemento e a outra com um elemento, conforme a reprodução do seu código abaixo:
x = [['horas_esperadas', 'preco']]
y = [['finalizado']]
Logo quando o train_test_split() tenta separar conjunto de dados ele acusa erro no tamanho da amostra (lembrando que y possui tamanho um), e gera esse erro que você encontrou.
Um detalhe, quando você faz seu dicionário mapa você usa 'unfinished':'incompletos', porém na aula o professor declara 'unfinished' : 'nao_finalizado'. Posteriormente o professor fez a troca de valores, onde era 0 passou a ser 1 e onde era 1 passou a ser 0. Você fez a troca certinha, porém renomeou para dados['completos'] = dados.incompletos.map(troca), aí na hora de fazer a declaração da variavel y você tentou acessar como o professor demonstrou,
usando finalizado. Uma dica é você usar os mesmos nomes utilizados pelo professor durante o curso.
mapa = {
'expected_hours' : 'horas_esperadas',
'price' : 'preco',
'unfinished' : 'nao_finalizado'
}
troca = {
0 : 1,
1 : 0
}
dados['finalizado'] = dados.nao_finalizado.map(troca)
dados.head()
Tenta substituir esse trecho da definição de x e y no seu notebook pelo trecho de código abaixo :
x = dados[['horas_esperadas', 'preco']]
y = dados[['completos']]No código acima estamos fazendo acesso ao conjunto de dados definido, assim o train_test_split() não acusará o tamanho da amostra e o código funciona como esperado, acessando o conjunto de dados correto.
Lembrando que o código passado acima está com os nomes de variáveis conforme o notebook enviado por você, então é só substituir e rodar.
Caso tenha alguma dúvida estou sempre à disposição.
Espero ter ajudado. :)