Boas Pedro!
Tudo bem?
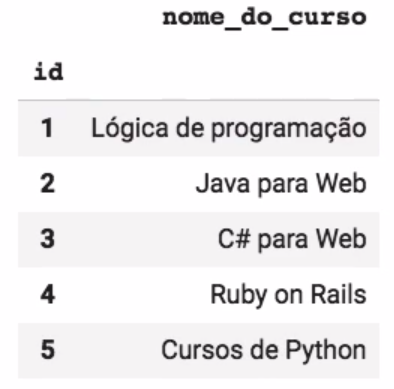
Isso ocorre porque o pandas diferencia visualmente as tabelas e os índices com essa identação diferente.
Para apresentar a tabela sem essa identação, pode-se fazer algumas coisas. Vou apresentar o modo que creio ser o mais eficiente
Uma das maneiras de apresentar o DataFrame da forma elegante é apresentar como markdown. Para isso, basta usar a função pd.to_markdown() que cria uma tabela em markdown a partir de um DataFrame. Primeiro, criei um DataFrame que replica o que você mostrou na sua questão:
import pandas as pd
nome_do_curso = ["Lógica de programação", "Java para Web", "C# para Web", "Ruby on Rails", "Cursos de Python"]
id = [1,2,3,4,5]
dados = pd.DataFrame()
dados["nome_do_curso"] = nome_do_curso
dados.index=id
dados.index.name="id"
Agora, para apresentar de uma forma mais eficiente, basta usar a função citada:
dados.to_markdown()
Que retorna a tabela:
| id | nome_do_curso |
|---|
| 1 | Lógica de programação |
| 2 | Java para Web |
| 3 | C# para Web |
| 4 | Ruby on Rails |
| 5 | Cursos de Python |
Dessa forma não há mais o problema com o id fora de identação.
Espero ter ajudado!
Bons Estudos!