
Olá tudo bem? Estou com algumas dúvidas quanto ao predict do modelo. Fui fazendo as aulas do curso e treinando o modelo. Porém, na hora de olhar o predict, fiz para um range(10), todos deram False.
# Normalização dos dados
imagens_treino = imagens_treino / float(255)
imagens_teste = imagens_teste/ float(255)
#Modelo
modelo = keras.Sequential([
keras.layers.Flatten(input_shape=(28,28)),
keras.layers.Dense(256, activation=tensorflow.nn.relu),
keras.layers.Dropout(0.2),
keras.layers.Dense(10, activation = tensorflow.nn.softmax)
])
# O aprendizado de máquina profundo necessita de uma compilação.
modelo.compile(optimizer = 'adam',
loss = 'sparse_categorical_crossentropy',
metrics=['accuracy'])
historico = modelo.fit(imagens_treino, identificacoes_treino, epochs=3, validation_split=0.2)
E os gráficos da accuracy e da loss estão abaixo:
plt.plot(historico.history['accuracy'])
plt.plot(historico.history['val_accuracy'])
plt.title('Acurácia por épocas')
plt.xlabel('épocas')
plt.ylabel('Acurácia')
plt.legend(['Treino', 'Validação'])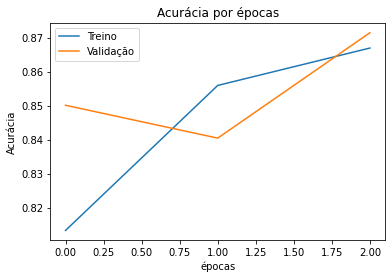
E o da Loss por época:
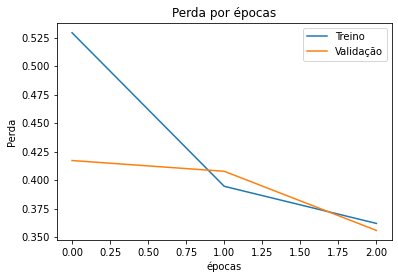
Quando fui olhar o predict, me parece que o modelo não se saiu bem.
teste = modelo.predict(imagens_teste)
for i in range(10):
print(np.argmax(teste[i]) == np.argmax(identificacoes_teste[i]))
Todos os prints resultaram em False. Contudo o evaluate do modelo me pareceu razoável:
perda_teste, acuracia_teste = modelo.evaluate(imagens_teste, identificacoes_teste)
print('Perda do teste :', perda_teste)
print('Acurácia do teste: ', acuracia_teste)
313/313 [==============================] - 1s 3ms/step - loss: 0.3850 - accuracy: 0.8597
Perda do teste : 0.38500356674194336
Acurácia do teste: 0.8597000241279602O que poderia ser feito para melhorar o predit, ou cometi algum erro que não percebi?
Muito obrigado.

