# Importando os pacotes do projeto
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
url = "https://raw.githubusercontent.com/alura-cursos/Estatisticas-Python-frequencias-medidas/refs/heads/main/dados/dados_desafio.csv"
dados = pd.read_csv(url)
dados.head()
dados.info()
dados['UF'].unique()
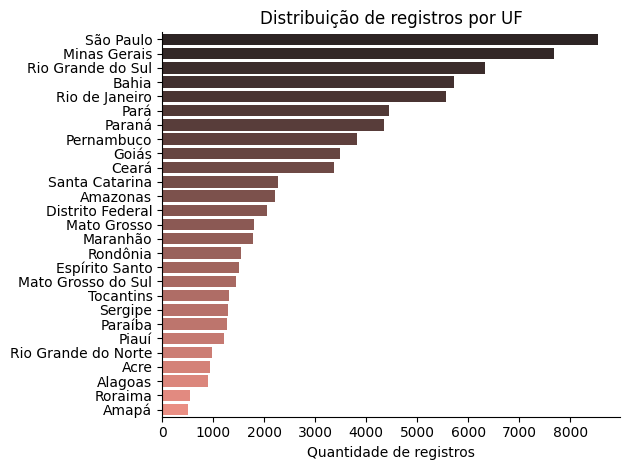
dados_uf = dados['UF'].value_counts().reset_index()
sns.barplot(data = dados_uf, y = 'UF', x = 'count', , palette = 'dark:salmon')
plt.title('Distribuição de registros por UF')
plt.ylabel('')
plt.xlabel('Quantidade de registros')
sns.despine()
plt.tight_layout()
plt.show()
# Definindo as variáveis
sexo = {0: 'Masculino', 1: 'Feminino'}
cor = {0:'Indígena', 2:'Branca', 4:'Preta', 6:'Amarela', 8:'Parda'}
anos_de_estudo = {1:'Sem instrução e menos de 1 ano', 2:'1 ano', 3:'2 anos', 4:'3 anos', 5:'4 anos', 6:'5 anos',
7:'6 anos', 8:'7 anos', 9:'8 anos', 10:'9 anos', 11:'10 anos', 12:'11 anos', 13:'12 anos',14:'13 anos',
15:'14 anos', 16:'15 anos ou mais', 17:'Não determinados'
dados['Sexo_categoria'] = pd.Categorical(dados['Sexo'], categories = [0,1], ordered = True)
dados['Sexo_categoria'] = dados['Sexo_categoria'].map(sexo)
dados['Cor_categoria'] = pd.Categorical(dados['Cor'], categories = [0, 2, 4, 6, 8 ], ordered = True)
dados['Cor_categoria'] = dados['Cor_categoria'].map(cor)
dados['Anos_estudo_categoria'] = pd.Categorical(dados['Cor'], categories = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17], ordered = True)
dados['Anos_estudo_categoria'] = dados['Anos_estudo_categoria'].map(anos_de_estudo)
print(f"Tivemos Renda a partir de R$ {min(dados['Renda']):,.2f} até R$ {max(dados['Renda']):,.2f}")