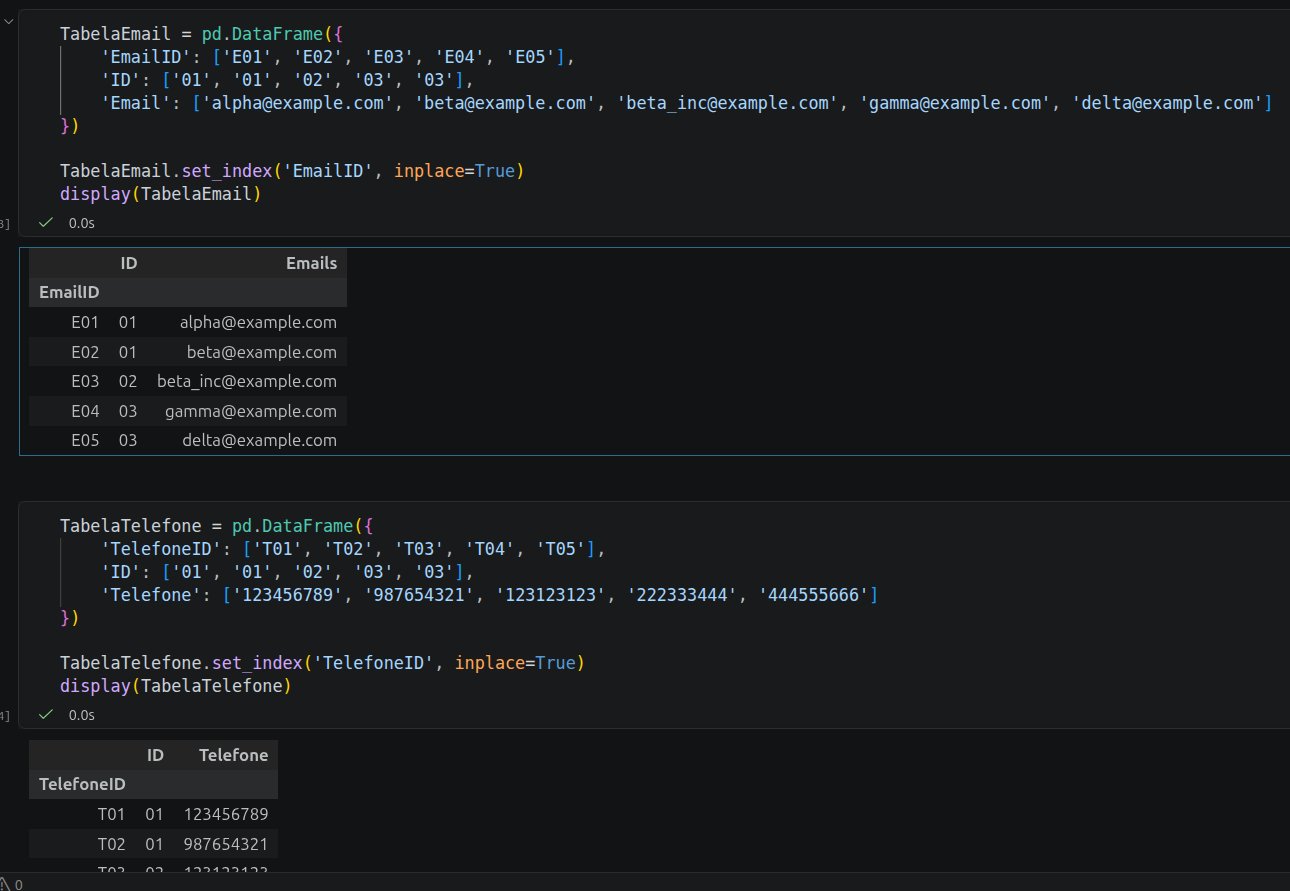
Eu procurei representar minha resposta usando a biblioteca pandas:
Você está vendo a versão anterior da nova experiência da Alura que estamos preparando para você. Em breve, ela ganha uma identidade visual novinha totalmente pensada em potencializar seus estudos!

Eu procurei representar minha resposta usando a biblioteca pandas:


Olá, William. Como vai?
Sensacional a sua iniciativa de utilizar a biblioteca Pandas e os DataFrames do Python para fixar os conceitos teóricos de modelagem e normalização de dados! Essa abordagem prática enriquece muito o aprendizado, pois conecta o design relacional de um banco de dados diretamente com as ferramentas que usamos no cotidiano da Ciência de Dados.
Analisando a sua estrutura de código e as tabelas resultantes na imagem, você aplicou com perfeição os conceitos da Primeira Forma Normal (1FN).
O grande objetivo da 1FN é eliminar a existência de atributos multivalorados e campos compostos, garantindo a atomicidade dos dados (onde cada célula da tabela armazena apenas um único valor).
Se esse cadastro estivesse em uma tabela não normalizada, provavelmente teríamos uma única linha por cliente com uma lista de e-mails separada por vírgula em uma única célula (ex: alpha@example.com, beta@example.com), o que tornaria buscas e junções extremamente complexas.
Ao criar as estruturas separadas:
ID como chave estrangeira para se conectar ao cliente original.ID de referência.Você garantiu tabelas limpas, atômicas e prontas para serem armazenadas de forma eficiente tanto em um banco de dados relacional (SQL) quanto para manipulação via Pandas.
Aproveitando que você estruturou seus dados em DataFrames separados utilizando as chaves primárias e estrangeiras corretas, o próximo grande passo para consolidar o estudo da modelagem é praticar o cruzamento dessas tabelas, simulando um comando JOIN do SQL.
No Pandas, você pode unir essas tabelas utilizando o método .merge(). Veja como é simples trazer o e-mail e o telefone do cliente com base na chave de correspondência que você criou:
# Realizando um merge interno baseado na coluna comum 'ID'
tabela_combinada = pd.merge(
TabelaEmail.reset_index(),
TabelaTelefone.reset_index(),
on='ID',
suffixes=('_email', '_tel')
)
display(tabela_combinada)
Essa junção vai criar um produto cartesiano para os IDs que possuem múltiplos registros (como o cliente 01, que tem dois e-mails e dois telefones), demonstrando de forma brilhante o comportamento de relacionamentos 1 para Muitos (1:N) na prática da manipulação de dados.
Parabéns pelo excelente nível do post e por elevar o nível do desafio utilizando código real!
Espero que possa ter lhe ajudado!