Você está vendo a versão anterior da nova experiência da Alura que estamos preparando para você. Em breve, ela ganha uma identidade visual novinha totalmente pensada em potencializar seus estudos!



Olá, Yonara! Como vai?
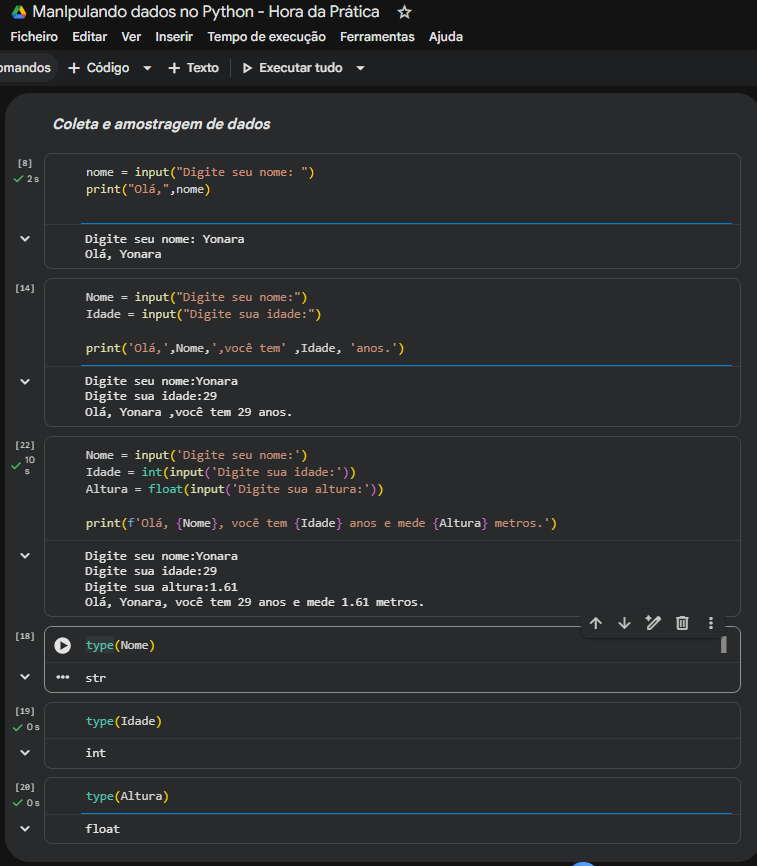
Que orgulho ver o print do seu Google Colab! O seu código está simplesmente impecável e muito bem estruturado. Dá para notar claramente a sua evolução passo a passo ao longo do desafio de Coleta e amostragem de dados.
Você começou com uma captura simples de texto, evoluiu para a junção de múltiplas variáveis e, no terceiro bloco, atingiu o nível ideal para uma futura Cientista de Dados: aplicou a conversão correta de tipos de dados (int e float) e coroou o código utilizando a elegância das f-strings. Os testes de conferência com a função type() no final fecharam o exercício com chave de ouro, provando que o Python guardou cada informação na caixinha certa!
Para enriquecer o seu tópico e ajudar os colegas que estão tentando entender a mecânica por trás desse desafio, vamos analisar visualmente o que o seu código fez perfeitamente nos bastidores da memória do computador.
Quando escrevemos códigos de análise de dados, o comportamento padrão do comando input() pode ser traiçoeiro. Como você bem validou com a função type(), o Python enxerga tudo o que é digitado no teclado inicialmente como uma String (texto).
Veja o mapeamento do que aconteceu no seu terceiro bloco de código:
Nome: O usuário digitou "Yonara". Como é texto puro, o Python salvou direto como str. Perfeito.Idade: Se você não tivesse usado o comando int(), o número 29 seria salvo como o texto "29". Isso impediria você de, por exemplo, somar mais um ano ou calcular a média de idade do grupo. Ao envelopar o código com int(input(...)), você quebrou o texto e salvou um Número Inteiro.Altura: Mesma lógica para números quebrados. O texto "1.61" passou pelo filtro do float() e transformou-se em um Número Real (ponto flutuante), pronto para cálculos estatísticos.Outro ponto que vale super a pena destacar para a comunidade do fórum é como o uso das f-strings no seu terceiro bloco deixou o resultado final muito mais profissional e limpo do que no segundo bloco.
Repare na sutil diferença de espaçamento no seu terminal:
Olá, Yonara ,você tem 29 anos.f-string): Você assume o controle total do texto. Os espaços acontecem única e exclusivamente onde você digitou dentro das aspas, gerando uma frase natural e perfeita: Olá, Yonara, você tem 29 anos e mede 1.61 metros.Parabéns pelo capricho na organização das células, pela escolha do tema escuro no Colab (que poupa bastante a nossa vista durante longas horas de código!) e pela precisão técnica na execução do desafio. Você começou com o pé direito no mundo do Python para Dados!
Espero que possa ter lhe ajudado!