Olá Murilo, tudo bem? Espero que sim!
Primeiro vou criar um DataFrame de exemplo, importanto a biblioteca pandas e numpy, pois ambas serão necessárias.
import pandas as pd
import numpy as np
idades = [18,17,26,23,18,17,20,23,19,18]
glicemia = [120,110,160,110,150,125,163,105,103,0]
dados = pd.DataFrame({'idades': idades, 'glicemia': glicemia})
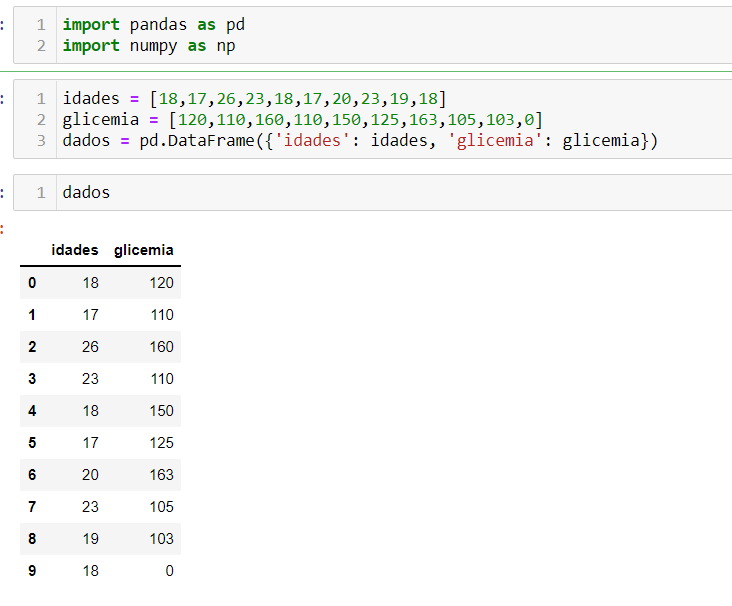
Respondendo as suas perguntas separadamente, temos:
1) Transformar valores nulos em NaN
Para transformar valores nulos em NaN, basta usar o seguinte código:
dados['glicemia'] = dados['glicemia'].replace(0, np.nan)
Dessa forma, a coluna com os dados da glicemia terão os valores 0 substituídos pelo objeto np.nan da biblioteca numpy.
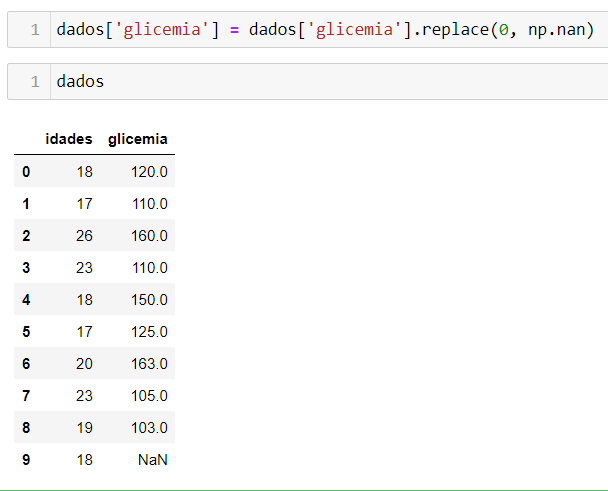
2) Substituir os missing values pela média dos pacientes de acordo com sua idade.
Para substituir os missing values, utilizaremos a função fillna() da biblioteca pandas. Como o intuito é substituir por valores dependendo da idade, vamos utilizar o groupby() para fazer o agrupamento pela idade e utilizar o transform() para aplicar as transformações a cada um dos grupos separadamente, fazendo uso de uma função lambda que aplicará o fillna() em cada um dos grupos x separadamente. Vamos reatribuir o resultado à coluna dados['glicemia']. O código ficará assim:
dados['glicemia'] = dados.groupby('idades').transform(lambda x: x.fillna(x.mean()))
O resultado final será:
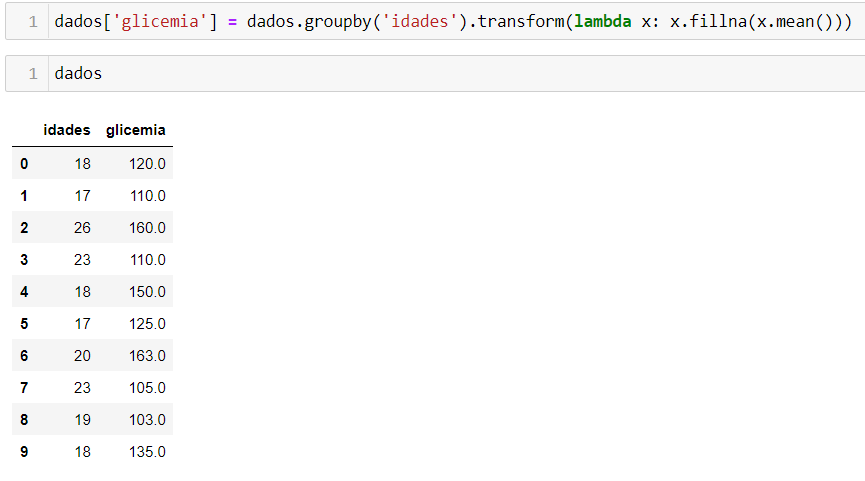
No exemplo apenas a glicemia com idade 18 foi substituída pela média da glicemia de idade correspondente a 18 anos, cuja média era 135.
Espero que tenha tirado sua dúvida.
Estou à disposição. Bons estudos!


