Olá, Felipe! Tudo bem com você?
A base de dados inicial é uma base desbalanceada, que quando levamos para modelos de machine learning introduzem vieses, portanto temos que realizar o balanceamento. No faça como eu fiz "dados desbalanceados" realizamos esse balanceamento e salvamos em uma variável chamada dados_final, portanto nossa base de dados agora possui:
0 5174
1 5174
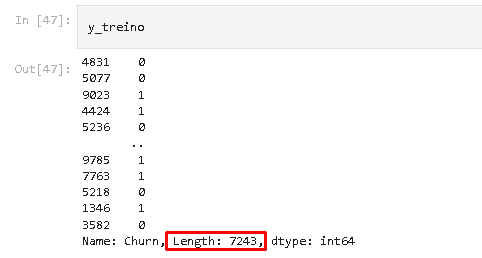
Totalizando 10348 amostras. Quando separamos 30% para teste e 70% para treino obtemos 0.7 * 10348 = 7243 amostras para treino, que é o que você encontrou.
Você pode conferir com mais detalhes todos os passos adotados no GitHub com essa aula, que está disponível nesse link.
Caso ainda possua alguma dúvida pode nos retornar por aqui mesmo.
Abraços.
Caso este post tenha lhe ajudado, por favor, marcar como solucionado ✓.Bons Estudos!