Olá, Amanda! Tudo bom?
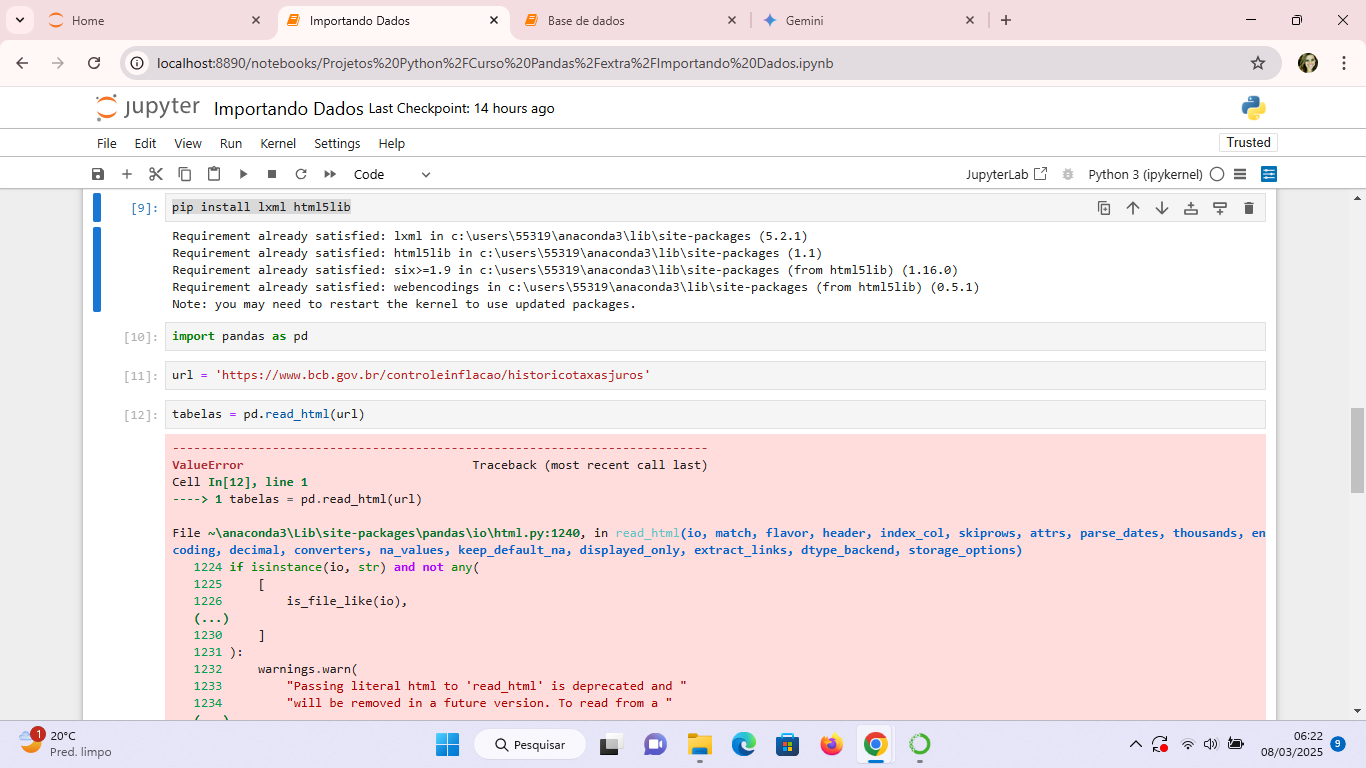
A mensagem do traceback é sobre a abordagem de leitura pd.read_html() ficará obsoleta no futuro. Mas recomendo que faça algumas revisões:
- Veja se a URL
https://www.bcb.gov.br/controleninflacao/historicotaxasjuros é válida e acessível. Abra-a em um navegador para confirmar se há tabelas HTML visíveis. Ao invés de passar a URL, você pode baixar o conteúdo HTML e passá-lo como string, isso te dará mais controle sobre o arquivo de download. - Vi que instalou as bibliotecas,
lxml, html5lib, instale também a beautifulsoup4 e requests. Porque pd.read_html() depende delas para parsear HTML - E tente reiniciar o kernel do Jupyter (como sugerido na mensagem).
Se o erro persistir, por favor, envie o traceback completo ou mais detalhes sobre o erro específico, dessa forma, ajudará a identificar a causa exata.
Espero que as sugestões sejam uteis e até mais, Amanda!
Caso este post tenha lhe ajudado, por favor, marcar como solucionado!