Olá Julio! Tudo bem com você?
Para tirar a mediana dos dados não é interessante que você faça essa separação apenas para os dados únicos daquela coluna. Isso porque, fazendo o cálculo dessa forma você não terá o mesmo resultado da mediana real, porque está eliminando os dados que seriam considerados no momento de encontrar a mediana.
O ideal é que você tire a mediana diretamente da coluna toda, pois todos os dados daquela coluna devem ser levados em consideração para o cálculo dessa mediana. Por exemplo:
mediana = dados_new['Valor'].median()
Quando você usa o método median ele automaticamente já ordena os dados antes de fazer o cálculo da mediana, então não é necessário ordená-los por meio do comando sort antes.
Em relação a esse desafio do professor, não existe exatamente uma resposta correta. Para que pudéssemos separar essa faixa de valores de forma precisa, precisaríamos ter algum valor mais discrepante nos nossos dados, que nos mostrasse essa diferença entre as possíveis diferentes classificações dos imóveis. No entanto, como podemos observar naquele histograma mostrado na aula:
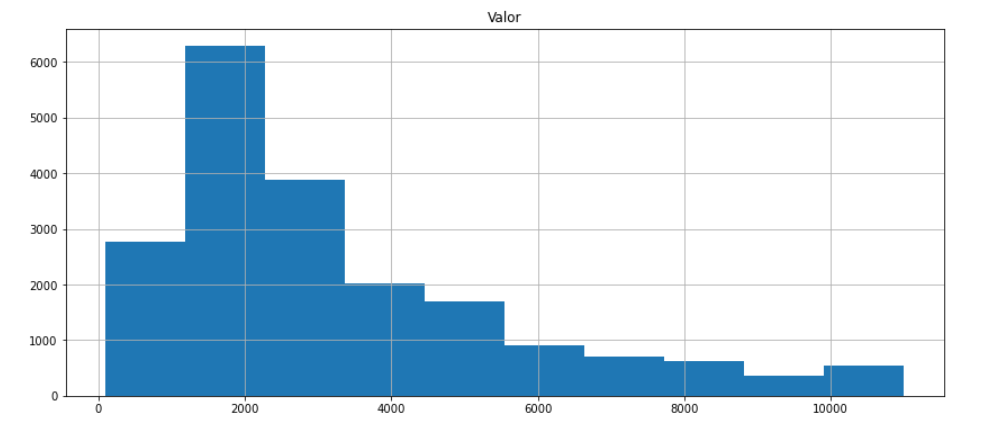
A distribuição dos valores se mostra bem comportada, o que dificulta a separação desses valores em duas classes distintas de imóveis de baixo padrão e alto padrão.
Sendo assim, acredito que uma forma de tentar fazer essa separação, seria analisar esse gráfico e separar os dados com base em algum valor que você julgar um pouco mais discrepante dos anteriores, por exemplo: vou definir que os imóveis de baixo padrão são aqueles que possuem valor abaixo de 3500.
alto_padrao = dados_new[dados_new['Valor'] > 3500]
baixo_padrao = dados_new[dados_new['Valor'] < 3500]
Mas não tem como sabermos se esse é o valor mais adequado, uma vez que nosso gráfico está bem comportado. Portanto, podemos ter diferentes respostas para esse desafio.
Espero que isso te ajude! Se ficar com alguma dúvida é só perguntar :)
Bons estudos!


