Não consigo importar a tabela da url https://www.tesourodireto.com.br/titulos/precos-e-taxas.htm estou tentando com o código
df_html = pd.read_html('https://www.tesourodireto.com.br/titulos/precos-e-taxas.htm')
len(df_html)
Você está vendo a versão anterior da nova experiência da Alura que estamos preparando para você. Em breve, ela ganha uma identidade visual novinha totalmente pensada em potencializar seus estudos!

Não consigo importar a tabela da url https://www.tesourodireto.com.br/titulos/precos-e-taxas.htm estou tentando com o código
df_html = pd.read_html('https://www.tesourodireto.com.br/titulos/precos-e-taxas.htm')
len(df_html)


Olá Junimar,
Esse erro SSLCertVerificationError indica que o Python não conseguiu verificar o certificado SSL do site que você está tentando acessar. Isso pode acontecer por várias razões, como o certificado do site estar expirado ou ser autoassinado.
Uma solução rápida para esse problema é desativar a verificação do certificado SSL ao fazer a solicitação HTTP. Você pode fazer isso adicionando o seguinte código antes de chamar o método read_html:
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
df_html = pd.read_html('https://www.tesourodireto.com.br/titulos/precos-e-taxas.htm')
len(df_html)Só que aparentemente a tabela desse site não é escrita com elementos html. Por isso, você não vai conseguir extrair os dados dessa forma.
A solução é que você pode encontrar o arquivo csv dessa página nesse link: https://www.tesourotransparente.gov.br/ckan/dataset/taxas-dos-titulos-ofertados-pelo-tesouro-direto/resource/796d2059-14e9-44e3-80c9-2d9e30b405c1
Aqui outro link com mais dados: https://www.tesourotransparente.gov.br/ckan/dataset?res_format=CSV&tags=Tesouro+Direto
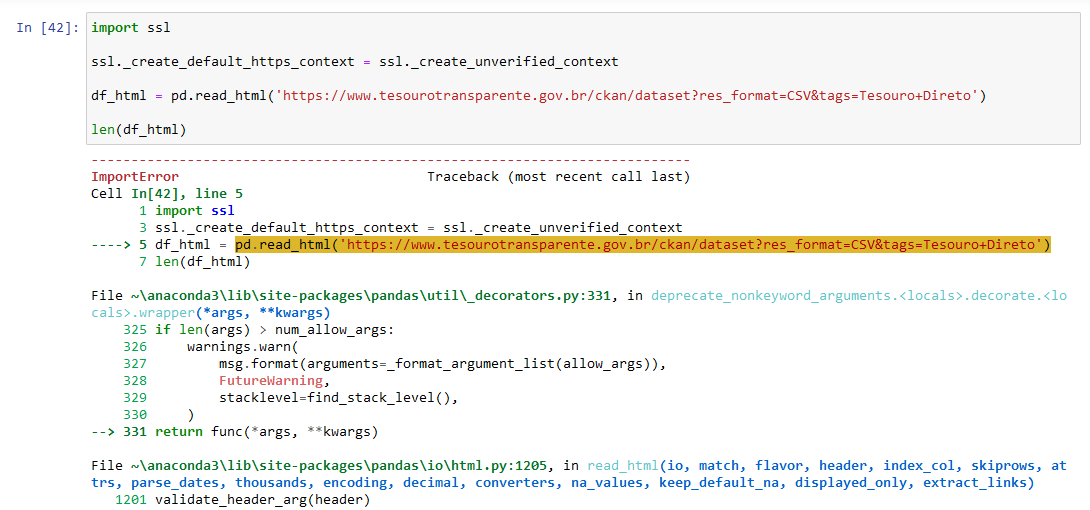
Boa noite Allan, tentei e não consegui com esse modelo. import ssl
ssl.createdefault_https_context = ssl.createunverified_context
df_html = pd.read_html('https://www.tesourotransparente.gov.br/ckan/dataset?res_format=CSV&tags=Tesouro+Direto')
len(df_html)
ImportError Traceback (most recent call last) Cell In[42], line 5 1 import ssl 3 ssl.createdefault_https_context = ssl.createunverified_context ----> 5 df_html = pd.read_html('https://www.tesourotransparente.gov.br/ckan/dataset?res_format=CSV&tags=Tesouro+Direto') 7 len(df_html)
File ~\anaconda3\lib\site-packages\pandas\util_decorators.py:331, in deprecate_nonkeyword_arguments..decorate..wrapper(args, **kwargs) 325 if len(args) > num_allow_args: 326 warnings.warn( 327 msg.format(arguments=formatargument_list(allow_args)), 328 FutureWarning, 329 stacklevel=find_stack_level(), 330 ) --> 331 return func(args, **kwargs)
File ~\anaconda3\lib\site-packages\pandas\io\html.py:1205, in read_html(io, match, flavor, header, index_col, skiprows, attrs, parse_dates, thousands, encoding, decimal, converters, na_values, keep_default_na, displayed_only, extract_links) 1201 validate_header_arg(header) 1203 io = stringify_path(io) -> 1205 return parse( 1206 flavor=flavor, 1207 io=io, 1208 match=match, 1209 header=header, 1210 indexcol=index_col, 1211 skiprows=skiprows, 1212 parse_dates=parse_dates, 1213 thousands=thousands, 1214 attrs=attrs, 1215 encoding=encoding, 1216 decimal=decimal, 1217 converters=converters, 1218 na_values=na_values, 1219 keep_default_na=keep_default_na, 1220 displayed_only=displayed_only, 1221 extract_links=extract_links, 1222 )
File ~\anaconda3\lib\site-packages\pandas\io\html.py:982, in parse(flavor, io, match, attrs, encoding, displayedonly, extract_links, **kwargs) 980 retained = None 981 for flav in flavor: --> 982 parser = parserdispatch(flav) 983 p = parser(io, compiled_match, attrs, encoding, displayed_only, extract_links) 985 try:
File ~\anaconda3\lib\site-packages\pandas\io\html.py:931, in parserdispatch(flavor) 929 if flavor in ("bs4", "html5lib"): 930 if not HASHTML5LIB: --> 931 raise ImportError("html5lib not found, please install it") 932 if not HASBS4: 933 raise ImportError("BeautifulSoup4 (bs4) not found, please install it")
ImportError: html5lib not found, please install it
Olá,
Aí ele está reclamando da falta da biblioteca html5lib. Você pode instalar com:
pip install html5libMas reitero que mesmo que instalando você não vai conseguir puxar a tabela com essa biblioteca. A solução que parece mais viável é recorrer ao csv que passei.