Olá, Lacerda
Tudo bem?
Primeiramente, gostaria de agradecer por compartilhar sua preocupação sobre a interpretação da matriz de confusão conosco.
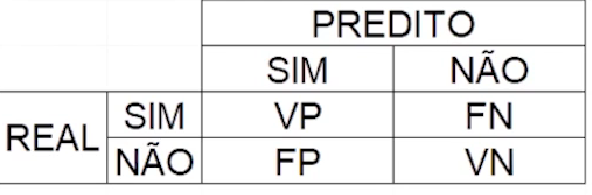
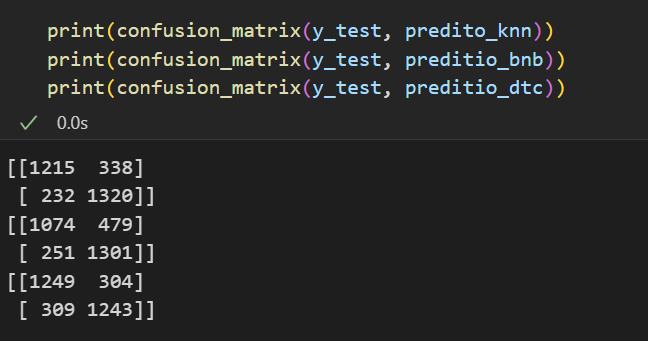
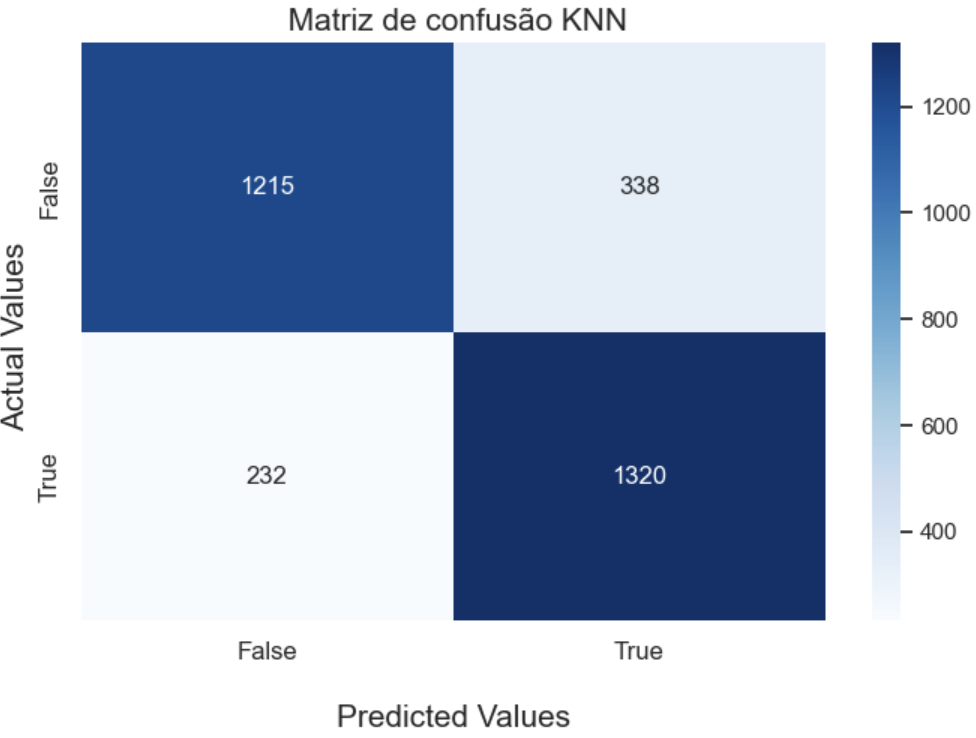
A matriz de confusão é uma ferramenta fundamental na avaliação do desempenho de algoritmos de classificação. Ela compara as previsões feitas por um modelo com os valores reais dos dados. Agora, em relação à disposição dos valores na matriz de confusão, pode haver uma pequena variação na forma como é apresentada.
A diferença entre os dois formatos é apenas na disposição dos valores, mas a interpretação é a mesma:
Verdadeiro Positivo (VP): Isso ocorre quando o modelo prevê corretamente que um exemplo pertence à classe positiva (1), e de fato, o exemplo pertence à classe positiva (1). Em outras palavras, o modelo acertou ao identificar um caso positivo.
Falso Positivo (FP): Nesse caso, o modelo prevê incorretamente que um exemplo pertence à classe positiva (1), quando na verdade, o exemplo pertence à classe negativa (0).
Falso Negativo (FN): Aqui, o modelo prevê erroneamente que um exemplo pertence à classe negativa (0), quando na verdade, o exemplo pertence à classe positiva (1).
Verdadeiro Negativo (VN): Isso ocorre quando o modelo prevê corretamente que um exemplo pertence à classe negativa (0), e de fato, o exemplo pertence à classe negativa (0). O modelo acertou ao identificar um caso negativo.
Independentemente da disposição, a interpretação dos valores permanece a mesma. Portanto, a diferença que você notou na figura não deve causar confusão na análise dos resultados.
Espero que esta explicação tenha esclarecido sua dúvida. Se você tiver mais perguntas ou precisar de ajuda adicional, por favor, não hesite em perguntar. Estamos aqui para ajudar!
Bons estudos!