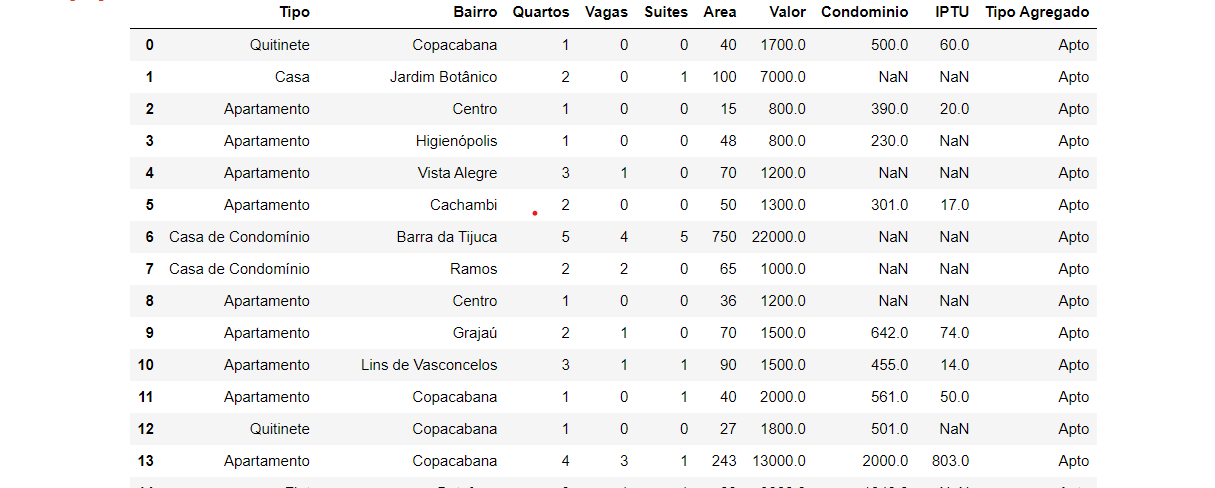
Que interessante Lyse! Muito bom mesmo.
Então vou aproveitar o laço for que você já enviou aqui, tudo bem? Vamos ajustar ele aqui.
Na primeira linha, ao utilizar for i in dados: isso está fazendo i ler todos os dados de dados e ler eles. No entanto, não é mais trabalho o i dentro desse código. Já na condicional if ('Casa' in str(dados['Tipo'])) foi transformada toda a Series em string mas, quando é utilizado o in para esse caso, é verificado se existe 'Casa' em toda a Series dados['Tipo'] e isso sempre vai ser verdade pois nessa Series sempre vai existir a palavra Casa. Por fim, a agregação dados['Tipo Agregado'] = 'Casa' não é correta pois para criar uma coluna nova, é preciso ter um conjunto de dados adequado, como uma lista, array ou uma Series para criar uma nova coluna.
Então, para o código que desejamos, podemos criar primeiro uma lista qualquer vazia para receber os dados para a nova coluna 'Tipo Agregado'. Depois criamos um laço for que vai percorrer todas as linhas da coluna 'Tipo' de dados dessa coluna:
lista = []
for tipos in dados['Tipo']:
Podemos utilizar tipos como um comparador pois ele representa todos os elementos da coluna Tipo. Assim, de acordo com a presença ou não da palavra 'Casa' em tipos iremos adicionar 'Casa' ou 'Apto' na lista que será a nova coluna 'Tipo Agregado'.
if ('Casa' in tipos):
lista.append('Casa')
else:
lista.append('Apto')
Por fim, adicionamos lista à coluna 'Tipo Agregado':
dados['Tipo Agregado'] = lista
dados.head()
E o resultado obtido será o mesmo obtido na resposta passada ^^
Vou deixar aqui o código completo caso queria testar:
lista = []
for tipos in dados['Tipo']:
if ('Casa' in tipos):
lista.append('Casa')
else:
lista.append('Apto')
dados['Tipo Agregado'] = lista
dados.head(10)
Outra opção é fazer a leitura linha por linha dos elementos de 'Tipo' separadamente, através da iteração pelas linhas do DataFrame:
lista = []
for linha in range(dados.shape[0]):
if ('Casa' in dados['Tipo'][linha]):
lista.append('Casa')
else:
lista.append('Apto')
dados['Tipo Agregado'] = lista
dados.head(10)
Note que é utilizado dados.shape[0] para coletarmos a quantidade de linhas em dados e é lido linha por linha da coluna 'Tipos'.
Os dois exemplos fazem a mesma tarefa, mas eu vejo o primeiro com uma leitura mais clara, portanto eu prefiro ele, mas vai do que você gostar também! Já o uso de contains não é tão indicado aqui, é mais adequado utilizar o in mesmo.
Eu espero que agora tenha ficado mais adaptado ao que você deseja fazer ^^ Se surgir outra dúvida estarei à disposição.
Bons estudos!
Caso este post tenha lhe ajudado, por favor, marcar como solucionado ✓. Bons Estudos!

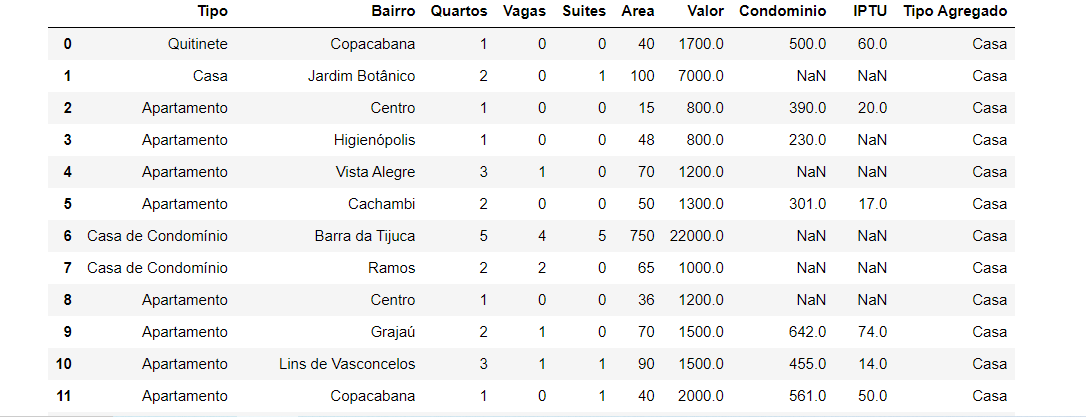 Tentei também sem o str, e não funcionou. Ficou tudo como Apto. Veja abaixo.
Porque? E o que é necessário fazer para funcionar?
Tentei também sem o str, e não funcionou. Ficou tudo como Apto. Veja abaixo.
Porque? E o que é necessário fazer para funcionar?