
Olá, pessoal! Eu consegui pegar esses dados do site da B3 e até consegui pegar apenas o conteúdo da tag.
<td class="text-center">114.355</td>
<td class="text-center">663.872.395</td>
<td class="text-center">13.281.572.347,49</td>
<td class="text-left">RRRP3T</td>
<td class="text-left">3R PETROLEUM ÓLEO E GÁS S.A</td>
<td class="text-left">ON NM</td>
<td class="text-right">331</td>
<td class="text-right">402.750</td>
<td class="text-right">16.659.428,80</td>
<td class="text-left">AERI3T</td>
<td class="text-left">AERIS IND. E COM. DE EQUIP. GERACAO DE ENERGIA S/A</td>
<td class="text-left">ON NM</td>
<td class="text-right">369</td>
<td class="text-right">1.320.200</td>
<td class="text-right">13.603.069,71</td>Consegui também fazer um split:
['114.355']
['663.872.395']
['13.281.572.347,49']
['RRRP3T']
['3R', 'PETROLEUM', 'ÓLEO', 'E', 'GÁS', 'S.A']
['ON', 'NM']
['331']
['402.750']
['16.659.428,80']
['AERI3T']
['AERIS', 'IND.', 'E', 'COM.', 'DE', 'EQUIP.', 'GERACAO', 'DE', 'ENERGIA', 'S/A']
['ON', 'NM']
['369']
['1.320.200']
['13.603.069,71']Mas quando tento transformar esses dados em uma lista,
dadosb3 = list(td.text.split())o que obtenho é apenas 1 dado, que é o último deles. Ele não está no fragmento dos dados que mandei, pois são muitos dados.
['9.054.333,18']Na verdade, eu precisaria transformar esses dados em um dataframe, mas como a aula é sobre listas, gostaria de aprender como fazer uma com esse tipo de dado. Será que alguém poderia me ajudar?



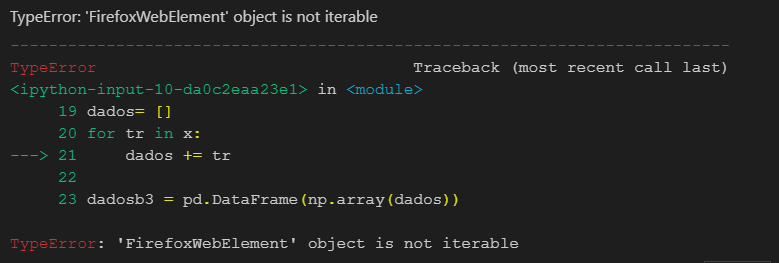 Você poderia continuar me ajudando? Obrigado!
Você poderia continuar me ajudando? Obrigado!