Você está vendo a versão anterior da nova experiência da Alura que estamos preparando para você. Em breve, ela ganha uma identidade visual novinha totalmente pensada em potencializar seus estudos!



Olá, Ivaney. Como vai?
Excelente postagem! Compartilhar as telas do ambiente de desenvolvimento (como o Google Colab ou Jupyter Notebook) ajuda muito a comunidade a visualizar o código e o resultado esperado lado a lado.
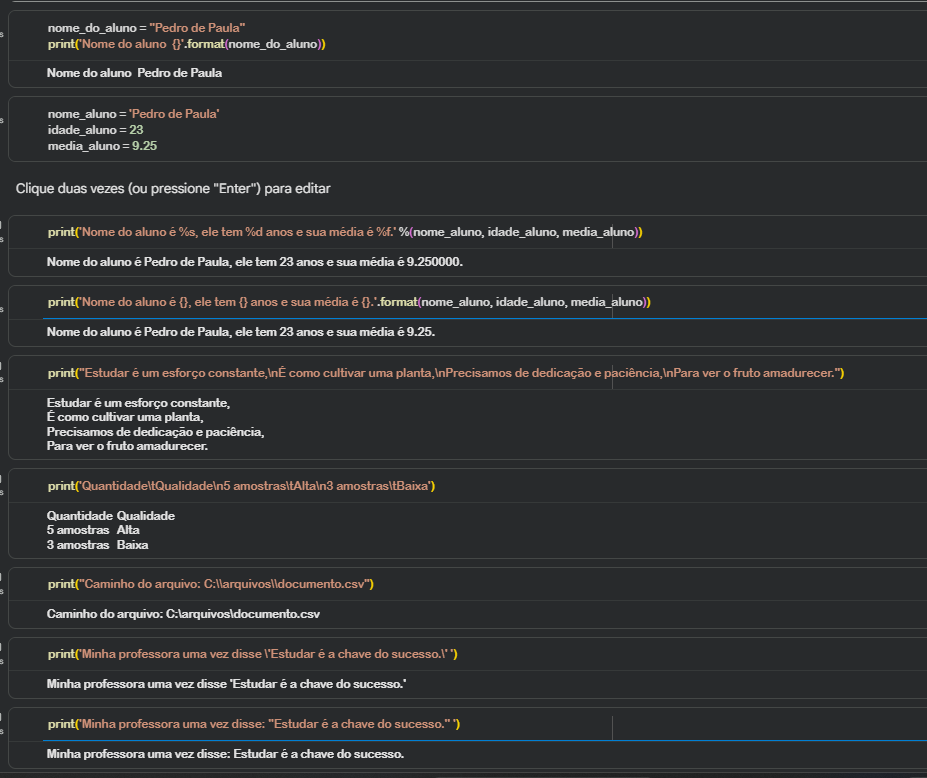
O seu caderno de estudos está completíssimo. Você passou pelos três pilares fundamentais da manipulação de strings na instrução print() do Python: a evolução histórica da formatação de dados, os caracteres de escape de fluxo (\n e \t) e a blindagem de caminhos de arquivos com barras duplas (\\).
Para enriquecer o seu tópico e fixar esses conceitos tão importantes para a análise de dados, separei três insights técnicos sobre o que você praticou:
%s ao .format()No início do seu print, você testou as duas abordagens tradicionais do Python para embutir variáveis em textos:
% (herdado da linguagem C), onde %s indica string, %d número inteiro e %f ponto flutuante. Repare no seu teste como o %f traz um comportamento padrão chato de exibir seis casas decimais (9.250000)..format(), que é mais moderno e limpo, pois utiliza as chaves {} como marcadores de posição genéricos, ajustando automaticamente a exibição do 9.25.f-stringsComo você está estudando os primeiros passos do Python para Dados, vale a pena adicionar ao seu caderno a terceira e mais atual forma de formatação: as f-strings (introduzidas a partir do Python 3.6).
Hoje, no mercado de Data Science, ela é a mais utilizada por ser a mais rápida para o computador processar e a mais fácil de ler. Em vez de usar o .format() no final, você coloca um f antes das aspas e escreve a própria variável direto dentro das chaves:
# O jeito mais moderno e utilizado no mercado hoje:
print(f"Nome do aluno é {nome_aluno}, ele tem {idade_aluno} anos e sua média é {media_aluno}.")
\\ em Engenharia de DadosO seu exemplo de caminho de arquivo ficou perfeito:print("Caminho do arquivo: C:\\arquivos\\documento.csv")
Esse é um conceito crítico! Na análise de dados, você passará muito tempo abrindo arquivos CSV ou Excel locais. Se você digitasse apenas uma barra (C:\arquivos), o Python tentaria interpretar o \a como um caractere especial de escape (que gera um alerta sonoro de sistema, o bell), quebrando a leitura do caminho.
Ao colocar a barra dupla \\, você faz o que chamamos de "escapar a barra", dizendo ao interpretador: "A primeira barra é só um aviso para você ignorar o efeito especial da segunda".
Parabéns pelo capricho nas anotações e pelos testes práticos abrangentes. Esse domínio da manipulação de textos facilitará muito o seu trabalho na hora de gerar relatórios e ler bases de dados!
Espero que possa ter lhe ajudado!