Oi, Arthur! Tudo bem contigo?
No primeiro momento temos que definir a diferença entre numpy array, dataset e DataFrame.
Numpy Array: É um conjunto de valores todos do mesmo tipo agrupados e acessados pelo índice. Podem ter mais de uma dimensão, mas ainda devem possuir o mesmo tipo de dado (numérico, booleano, string...)
Dataset: É sua base de dados. É o arquivo csv, por exemplo.
DataFrame: É uma tabela de dados em formato retangular e possui uma coleção ordenada de colunas, onde cada coluna pode ter um tipo de valor diferente (numérico, booleano, string...)
E um conceito que vai aparecer mais pra frente que é de Series:
- Series: é um objeto do tipo array de apenas uma dimensão que possui uma sequência de valores e um array de rótulos que chamamos de índice. Pode pensar neles como um DataFrame de apenas uma coluna, pois um DataFrame são várias Series juntas.
Então o DataFrame pode ser criado a partir de seu numpy array. Abaixo um exemplo de como podemos fazer isso:
import pandas as pd
import numpy as np
teste = pd.DataFrame(np.arange(16).reshape((4,4)))
teste
Saída:
| 0 | 1 | 2 | 3 |
|---|
| 0 | 0 | 1 | 2 | 3 |
| 1 | 4 | 5 | 6 | 7 |
| 2 | 8 | 9 | 10 | 11 |
| 3 | 12 | 13 | 14 | 15 |
Também pode ser criado a partir também do seu dataset, fazendo a importação do seu arquivo csv (ou outro tipo de arquivo), conforme nosso exemplo um pouco mais abaixo.
Como o que você tem é um DataFrame (Observe que são vários tipos de dados, a coluna home_score são inteiros, já coluna city são strings) a forma que você está tentando acessá-lo não é a correta.
Para acessar as colunas do DataFrame basta apenas passar seu nome e a coluna.
nome_do_dataframe['nome_da_coluna']
Vamos agora ao exemplo que você está tentando fazer, onde utilizaremos a abordagem do ou, que é escrito pelo símbolo: |. Há algumas abordagens para o que você está tentando fazer, vou mostrar uma delas, tudo bem?
import pandas as pd
import numpy as np
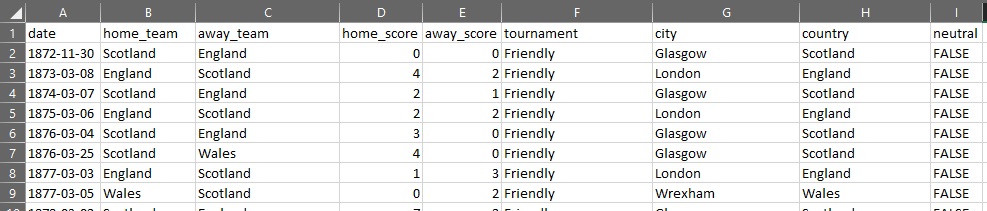
dataset = pd.read_csv('results.csv')
dataset.head()
Saída:
| date | home_team | away_team | home_score | away_score | tournament | city | country | neutral |
|---|
| 0 | 1872-11-30 | Scotland | England | 0 | 0 | Friendly | Glasgow | Scotland | False |
| 1 | 1873-03-08 | England | Scotland | 4 | 2 | Friendly | London | England | False |
| 2 | 1874-03-07 | Scotland | England | 2 | 1 | Friendly | Glasgow | Scotland | False |
| 3 | 1875-03-06 | England | Scotland | 2 | 2 | Friendly | London | England | False |
| 4 | 1876-03-04 | Scotland | England | 3 | 0 | Friendly | Glasgow | Scotland | False |
No código acima estamos apenas fazendo a importação do dataset, que está em csv, e colocando em um DataFrame que chamamos de dataset. Encontrei o dataset usado por você nesse link.
O_M = dataset['tournament'] != 'Friendly'
dataset_sem_friendly = dataset[O_M]
dataset_sem_friendly.head()
Saída:
| date | home_team | away_team | home_score | away_score | tournament | city | country | neutral |
|---|
| 29 | 1884-01-26 | Northern Ireland | Scotland | 0 | 5 | British Championship | Belfast | Republic of Ireland | False |
| 30 | 1884-02-09 | Wales | Northern Ireland | 6 | 0 | British Championship | Wrexham | Wales | False |
| 31 | 1884-02-23 | Northern Ireland | England | 1 | 8 | British Championship | Belfast | Republic of Ireland | False |
| 32 | 1884-03-15 | Scotland | England | 1 | 0 | British Championship | Glasgow | Scotland | False |
| 33 | 1884-03-17 | Wales | England | 0 | 4 | British Championship | Wrexham | Wales | False |
No código acima estamos fazendo a seleção de todas as linhas do nosso DataFrame que não possuem Friendly na coluna tournament, fazemos então um novo DataFrame (dataset_sem_friendly) com base nessa seleção.

 Eu criei um novo array O_M (Official Matches) para filtrar apenas jogos oficiais
Eu criei um novo array O_M (Official Matches) para filtrar apenas jogos oficiais
