Prezados tudo bem?
Estou agora em agosto de 2024 fazendo esse treinamento e, por esse motivo já não conto mais com a versão disponível (gratuita) da área de desenvolvedor no Twitter, que passou a ser pago graças ao Sr. Ellon Musk.
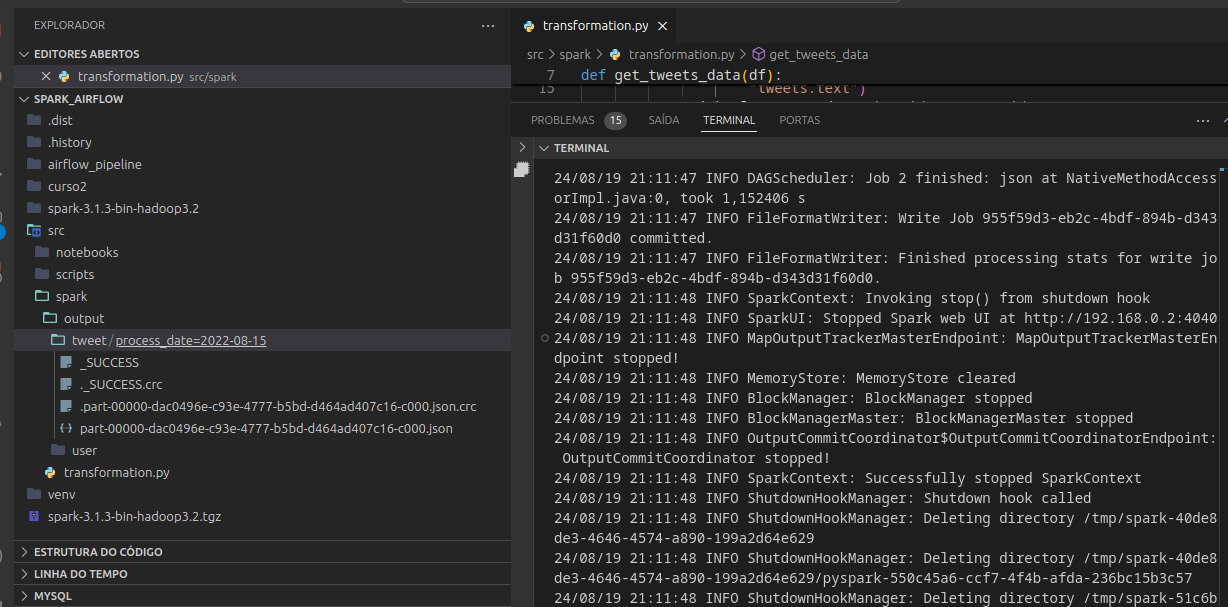
Pois bem, desde o curso anterior estou usando arquivos simulando tweets hospedados no site https://labdados.com e, coincidência ou não, não estava dando certo a execução do spark submit, especificamente a seguinte linha de comando:
./bin/spark-submit /home/marcio-estevam/Documentos/Spark_Airflow/src/spark/transformation.py --src /home/marcio-estevam/Documentos/Spark_Airflow/curso2/datalake/twitter_datascience --dest /home/marcio-estevam/Documentos/Spark_Airflow/src/spark/output --process_date 2022-08-15
Os erros apresentados eram de não encontrar no df os nomes modificados durante o processo de elaboração do notebook e, revendo esse campo onde ocorre essa remarcação dos nomes estava assim:
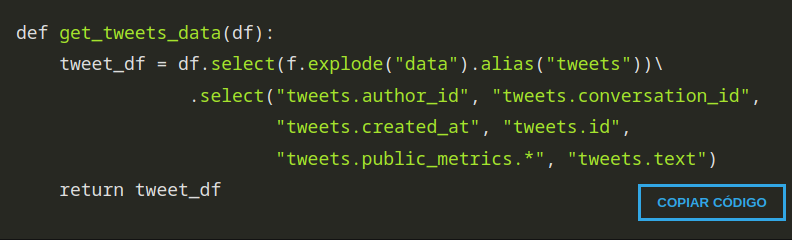
Porém, tive que alterar para o seguinte:

Para renomear as colunas corretamente.
Após isso, o script rodou perfeitamente: