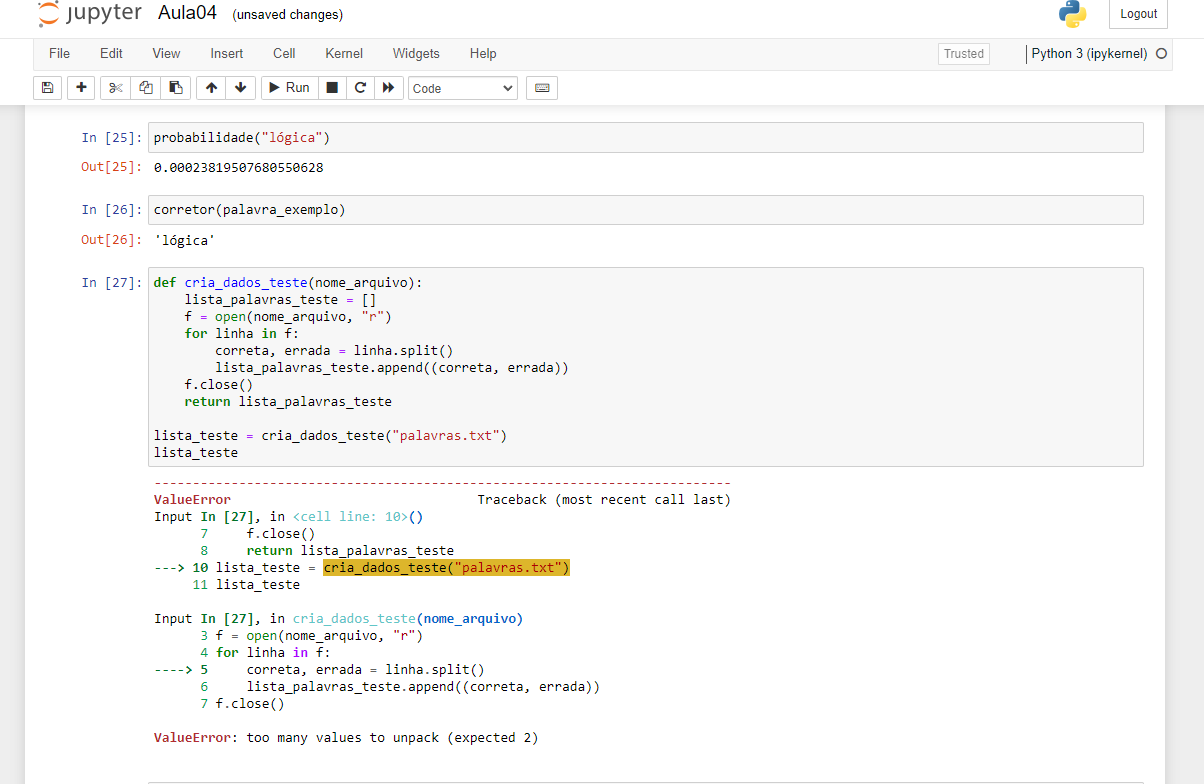
No curso postado no ano de 2020 o código funciona porém mesmo após fielmente copiado não funciona, não consigo encontrar o erro o que gera o erro "too many values to unpack (expected 2)" para dar segmento ao projeto.
Você está vendo a versão anterior da nova experiência da Alura que estamos preparando para você. Em breve, ela ganha uma identidade visual novinha totalmente pensada em potencializar seus estudos!

No curso postado no ano de 2020 o código funciona porém mesmo após fielmente copiado não funciona, não consigo encontrar o erro o que gera o erro "too many values to unpack (expected 2)" para dar segmento ao projeto.


Olá, Esdras, tudo bem?
Parece que o código está tentando ler cada linha da sua lista lista_teste e não está vendo apenas dois valores. Ou seja, provavelmente pode ser algum problema na lista_teste que está ocasionando esse erro. O meu palpite está no caso que talvez a sua tupla com a palavra correta e a errada não está como o professor apresentou em aula.
Seria possível você rodar o código lista_teste em uma célula separada e mandar o print da saída aqui para que eu possa verificar se o erro estaria na lista?
Fico no aguardo e agradeço desde já!
Ainda não consegui, fiz umas mudanças mas ainda não resolvi. 1° Tentativa de correção 2° Modificação solicitada 3° Arquivo original disponibilizado pela plataforma
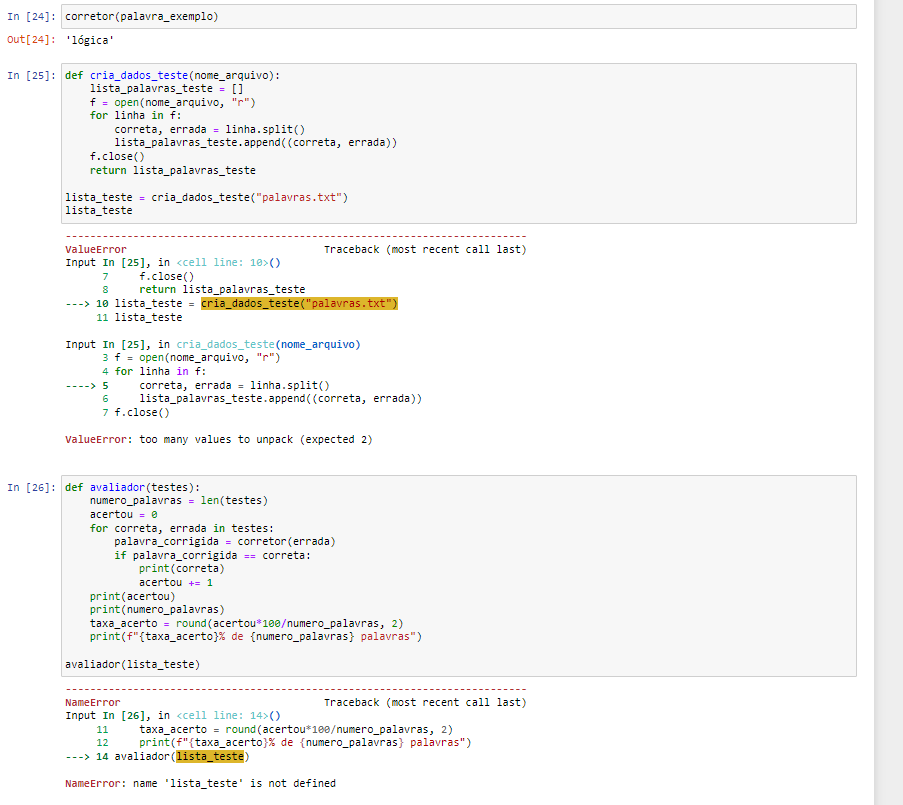
Python 3 Função que funcionou:
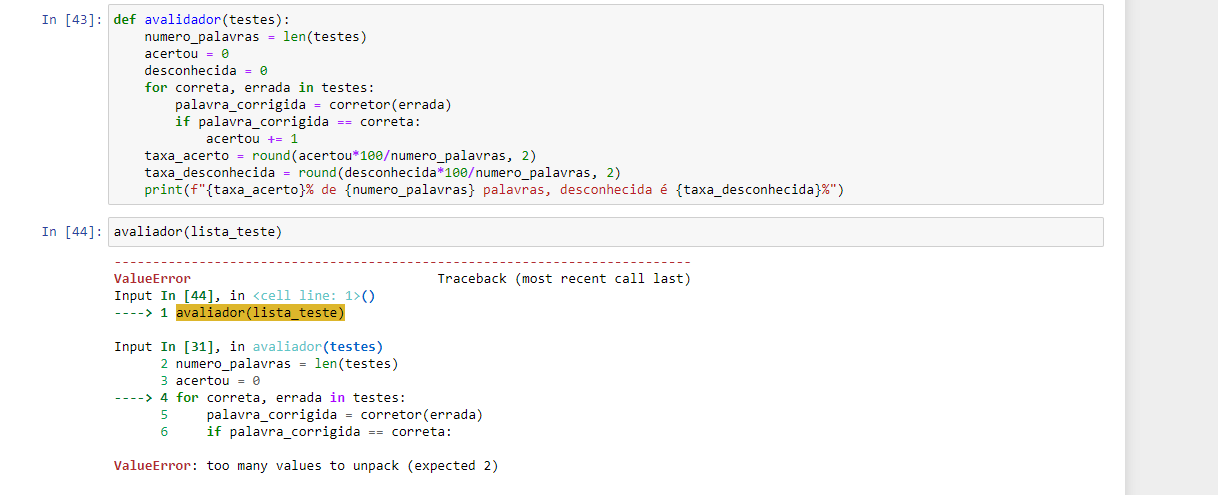
def cria_dados_teste(nome_arquivo):
lista_palavras_teste = []
f = open(nome_arquivo, "r")
for linha in f:
total_linhas = linha.split()
lista_palavras_teste.append(total_linhas)
f.close()
return lista_palavras_teste
lista_teste = cria_dados_teste("palavras.txt")
lista_testeFunção disponibilizada pela plataforma:
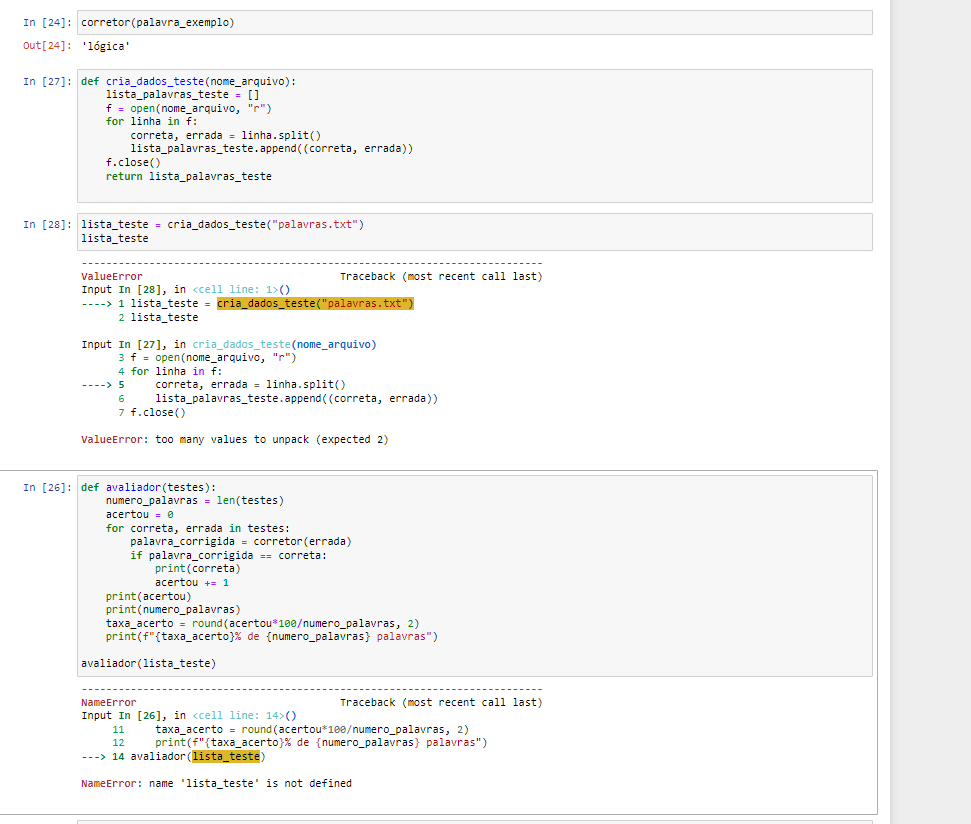
def cria_dados_teste(nome_arquivo):
lista_palavras_teste = []
f = open(nome_arquivo, "r")
for linha in f:
correta, errada = linha.split()
lista_palavras_teste.append((correta, errada))
f.close()
return lista_palavras_testeFunção que rodou porém gera o erro "too many values to unpack (expected 2)"
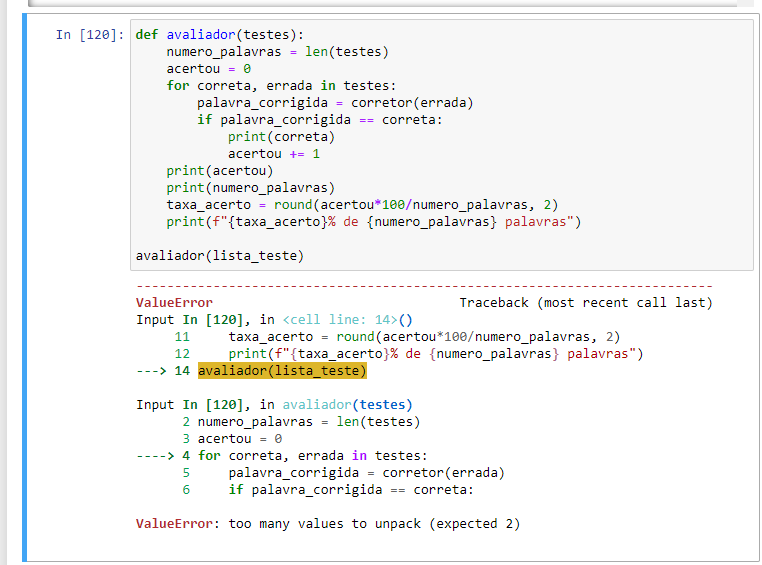
def avaliador(testes):
numero_palavras = len(testes)
acertou = 0
for correta, errada in testes:
palavra_corrigida = corretor(errada)
if palavra_corrigida == correta:
print(correta)
acertou += 1
print(acertou)
print(numero_palavras)
taxa_acerto = round(acertou*100/numero_palavras, 2)
print(f"{taxa_acerto}% de {numero_palavras} palavras")
avaliador(lista_teste)Achei bem estranho esse erro estar acontecendo... Parece que o erro está no arquivo palavras.txt, pois ele já aponta erro na criação das variáveis correta e errada fazendo o split da linha.
Você consegue verificar se o arquivo palavras.txt que você fez upload no colab está de uma forma semelhante a abaixo? Com cada dupla de palavras em linhas separadas e com um espaço entre elas?
Para verificar dentro do colab é só clicar no arquivo palavras.txt que você fez o upload que ele abrirá na lateral da tela uma visualização do arquivo.

Fico no aguardo!
Boa tarde, não usei o colab mas usei o jupyter, a saída está de cada item e sua devida correção por linha. Mas até mesmo o arquivo baixado no fim do módulo não da certo a não ser que troque os valores passados no for 'correta, errada'. Fiz o teste e no colab funciona
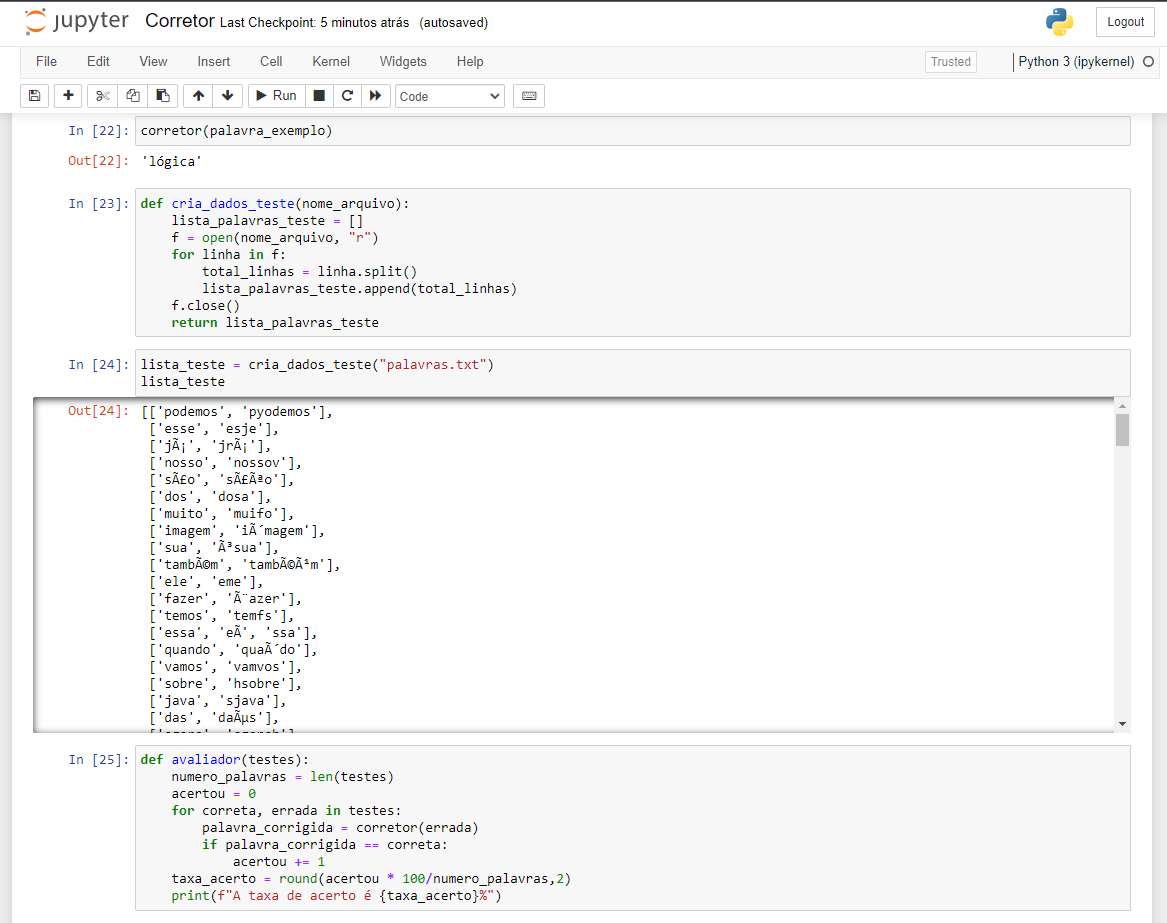
Código disponibilizado no final da aula 4