Olá. De acordo com o curso eu utilizei a função SMOTE corretamente, chequei as minhas variaveis (X_treino e y_treino) e elas estão corettamente tratadas. Porém o meu código retornou o seguinte erro:
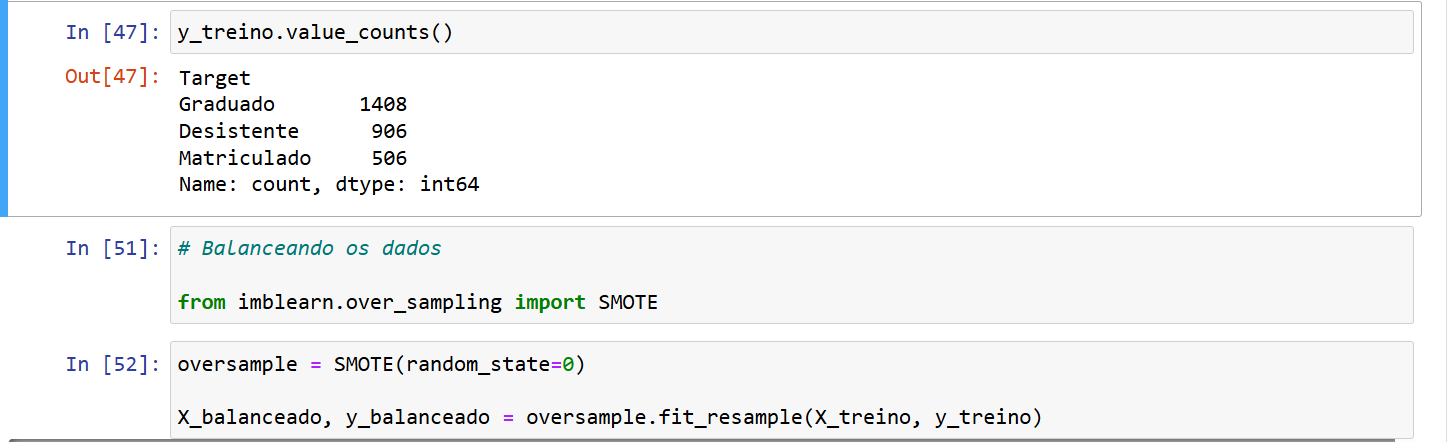

Poderia me ajudar ?
Você está vendo a versão anterior da nova experiência da Alura que estamos preparando para você. Em breve, ela ganha uma identidade visual novinha totalmente pensada em potencializar seus estudos!

Olá. De acordo com o curso eu utilizei a função SMOTE corretamente, chequei as minhas variaveis (X_treino e y_treino) e elas estão corettamente tratadas. Porém o meu código retornou o seguinte erro:
Poderia me ajudar ?


Oi, Guilherme! tudo bem?
Tente imprimir X_treino e y_treino antes de realizar o balanceamento para confirmar que eles contêm os dados esperados.
Se você puder fornecer mais informações sobre como X_treino e y_treino foram preparados ou outras partes relevantes do seu código, eu consigo te ajudar melhor!
Fico no aguardo das informações :)
Olá Valquíria, tudo bem ?
Os códigos abaixo mostra como as variáveis X_treino e y_treino foram preparadas.
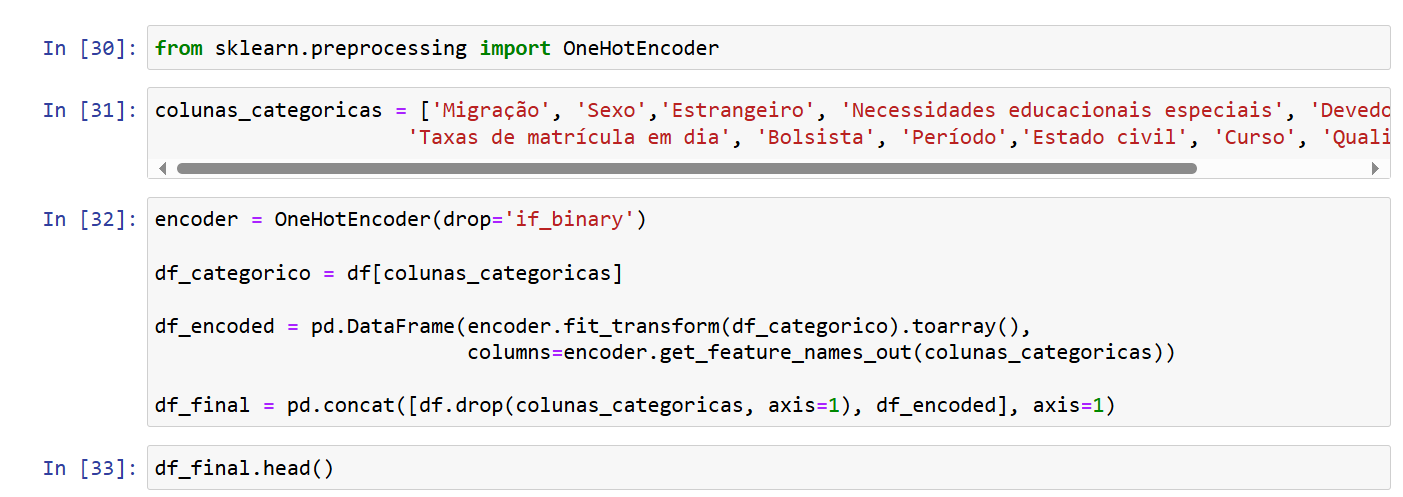
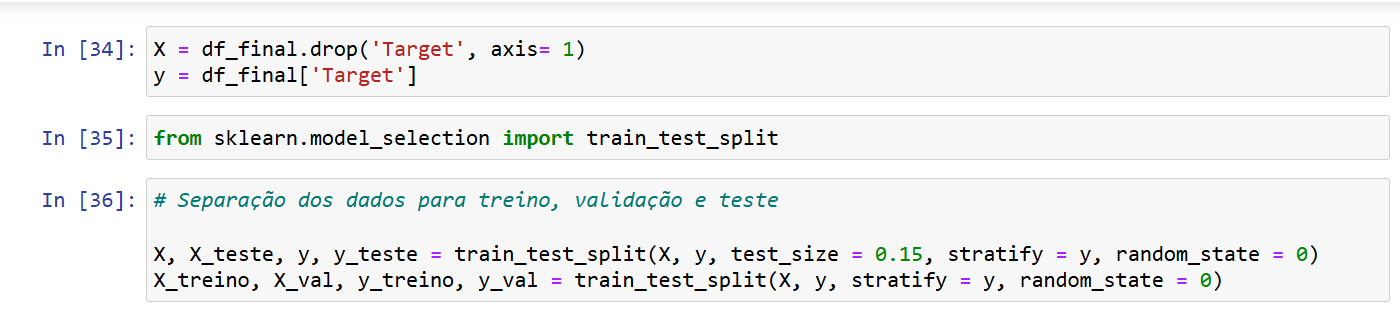
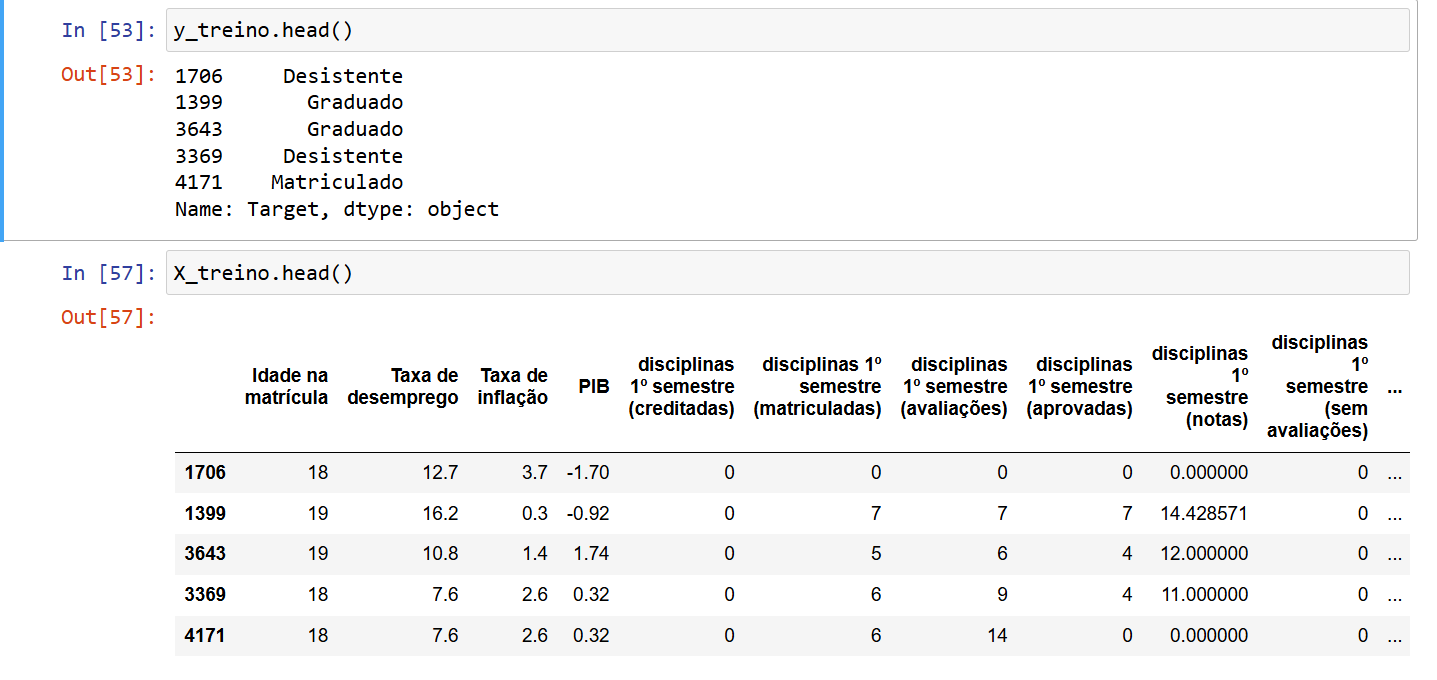
Guilherme, obrigada por enviar os códigos!
O erro "NoneType object has no attribute 'split'" geralmente ocorre quando uma variável que deveria ser um objeto (como uma string ou um DataFrame) é, na verdade, None. Porém, eu rodei o notebook todo aqui com os códigos do curso e não gerou nenhum erro.
Vamos repassar cada trecho de código para garantir que tudo esteja correto e ajudar você a executar novamente:
Primeiro, vamos codificar as colunas categóricas usando o OneHotEncoder.
from sklearn.preprocessing import OneHotEncoder
colunas_categoricas = ['Migração', 'Sexo','Estrangeiro', 'Necessidades educacionais especiais', 'Devedor',
'Taxas de matrícula em dia', 'Bolsista', 'Período','Estado civil', 'Curso', 'Qualificação prévia']
# Selecionando apenas as colunas categóricas do dataframe
df_categorico = df[colunas_categoricas]
# Inicializando o OneHotEncoder
encoder = OneHotEncoder(drop='if_binary')
# Ajustando e transformando os dados, criando um novo dataframe com as colunas codificadas
df_encoded = pd.DataFrame(encoder.fit_transform(df_categorico).toarray(),
columns=encoder.get_feature_names_out(colunas_categoricas))
# Combinando as colunas codificadas com as colunas não codificadas do dataframe original
df_final = pd.concat([df.drop(colunas_categoricas, axis=1), df_encoded], axis=1)
Depois de codificar os dados, vamos separar as variáveis independentes (X) da variável dependente (y).
X = df_final.drop('Target', axis=1)
y = df_final['Target']
Vamos dividir os dados em conjuntos de treino, teste e validação.
from sklearn.model_selection import train_test_split
X, X_teste, y, y_teste = train_test_split(X, y, test_size=0.15, stratify=y, random_state=0)
X_treino, X_val, y_treino, y_val = train_test_split(X, y, stratify=y, random_state=0)
Finalmente, aplicamos o SMOTE para balancear os dados de treino.
from imblearn.over_sampling import SMOTE
oversample = SMOTE(random_state=0)
X_balanceado, y_balanceado = oversample.fit_resample(X_treino, y_treino)
Para garantir que as variáveis não estejam None, você pode adicionar verificações antes de aplicar o SMOTE:
# Verificar se X_treino e y_treino não são None
if X_treino is None or y_treino is None:
raise ValueError("X_treino ou y_treino está com valor None. Verifique o carregamento dos dados.")
# Verificar o tipo dos dados
print(f"Tipo de X_treino: {type(X_treino)}")
print(f"Tipo de y_treino: {type(y_treino)}")
# Verificar a forma dos dados
print(f"Forma de X_treino: {X_treino.shape}")
print(f"Forma de y_treino: {y_treino.shape}")
# Aplicar o SMOTE
oversample = SMOTE(random_state=0)
X_balanceado, y_balanceado = oversample.fit_resample(X_treino, y_treino)
print("Balanceamento feito com sucesso!")
print(f"Nova forma de X_balanceado: {X_balanceado.shape}")
print(f"Nova forma de y_balanceado: {y_balanceado.shape}")
Espero que isso ajude a resolver o problema. Tente executar os códigos novamente e, se houver qualquer dúvida ou problema, estou aqui para ajudar!
Valquíria infelizmente o código ainda não funcionou. Mesmo eu executando os códigos que você me forneceu, eu tive retorno do mesmo erro. O que pode ser esse tipo de problema ?
Guilherme,
Gostaria de saber como foi o teste com o código que te enviei. Conseguiu rodar essa verificação?
# Verificar se X_treino e y_treino não são None
if X_treino is None or y_treino is None:
raise ValueError("X_treino ou y_treino está com valor None. Verifique o carregamento dos dados.")
# Verificar o tipo dos dados
print(f"Tipo de X_treino: {type(X_treino)}")
print(f"Tipo de y_treino: {type(y_treino)}")
# Verificar a forma dos dados
print(f"Forma de X_treino: {X_treino.shape}")
print(f"Forma de y_treino: {y_treino.shape}")
# Aplicar o SMOTE
oversample = SMOTE(random_state=0)
X_balanceado, y_balanceado = oversample.fit_resample(X_treino, y_treino)
print("Balanceamento feito com sucesso!")
print(f"Nova forma de X_balanceado: {X_balanceado.shape}")
print(f"Nova forma de y_balanceado: {y_balanceado.shape}")
Se por acaso o erro persistir, uma boa prática é comparar diretamente o seu código com a versão que disponibilizamos no curso. Você pode baixar o notebook desta aula no início da próxima aula e fazer uma comparação lado a lado para identificar qualquer discrepância que possa estar causando o problema.
Estou aqui para te ajudar a resolver isso, então me conta o que aconteceu quando você rodou o teste!
Esse código retornou o mesmo erro, logo depois dos prints solicitados.


Você poderia tentar executar os códigos no Google Colab para verificarmos se o ambiente pode estar influenciando os resultados? Às vezes, pequenas diferenças entre o Colab e o Jupyter Notebook podem afetar a execução dos códigos.
Aqui está uma sugestão de como fazer isso:
Se o problema for resolvido usando o Colab, isso pode indicar que há alguma configuração ou versão de biblioteca diferente no seu Jupyter Notebook local que está causando o erro. Caso contrário, continuaremos investigando para encontrar a solução.
Estou à disposição para acompanhar todo o processo e ajudar no que for necessário. Me avise como foi a experiência no Colab!