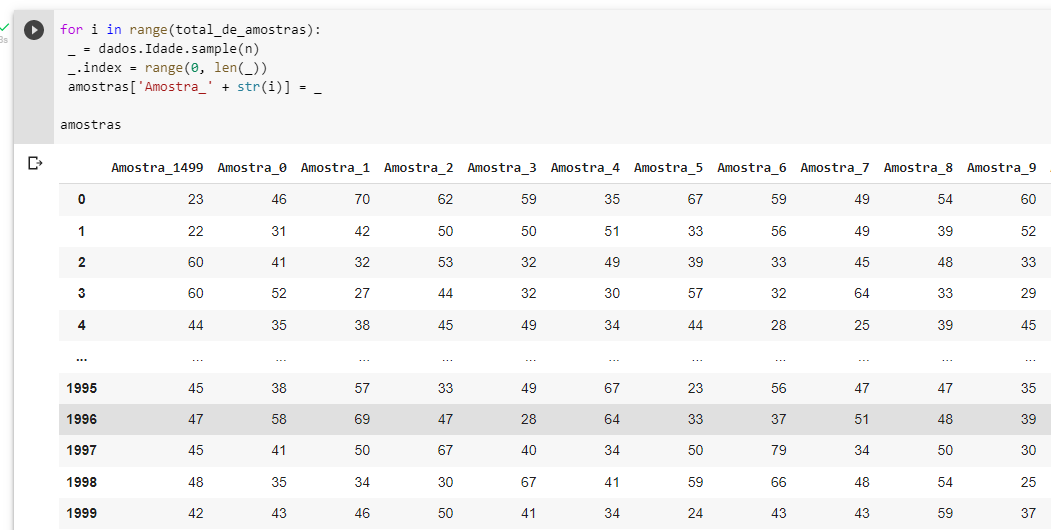
Como pode ser visto na imagem estou tendo problema na ordem dos index começando "Amostra_1499"
Você está vendo a versão anterior da nova experiência da Alura que estamos preparando para você. Em breve, ela ganha uma identidade visual novinha totalmente pensada em potencializar seus estudos!

Como pode ser visto na imagem estou tendo problema na ordem dos index começando "Amostra_1499"


Olá Matheus, tudo bem? Espero que sim!
Provavelmente isso ocorreu porque a linha de código amostras['Amostra_' + str(i)] = _ estava do lado de fora do bloco for, criando uma tabela inicialmente só com a última amostra 1499.
for i in range(total_de_amostras):
_ = dados.Idade.sample(n)
_.index = range(0, len(_))
amostras['Amostra_' + str(i)] = _
amostrasAo corrigir a indentação para dentro do for, a tabela foi novamente criada, porém a coluna amostra_1499 se manteve no início. O código correto é o seguinte:
for i in range(total_de_amostras):
_ = dados.Idade.sample(n)
_.index = range(0, len(_))
amostras['Amostra_' + str(i)] = _
amostrasCaso queira criar a tabela do zero corretamente, rode a célula anterior, correspondendo ao código:
amostras = pd.DataFrame()Dessa forma a tabela será zerada e o código do for criará a tabela na ordem certa.
Espero que tenha tirado sua dúvida.
Estou à disposição. Bons estudos!
João, obrigado entendi o erro.
Estou estudando e gostaria de saber como crio um DataFrame a partir de um DataFrame, por exemplo: há 101 países listados mas alguns se repetem centenas de vezes. Como faço pra criar DataFrame individual pra cada país? Esse DataFrame contendo todas as repetições
Olá Matheus,
Para filtrar por um determinado país, basta fazer uso da indexação booleana da biblioteca pandas, passando como condição o critério de igualdade da coluna country o nome do país de interesse. Dessa forma, você obtém um DataFrame exclusivo para aquele país, podendo visualizar somente aqueles dados ou salvar em um arquivo à parte.
Deixo abaixo a forma de se realizar com dados de exemplo:
import pandas as pd
dados = pd.DataFrame({'country':['Albania','Albania','Brazil','Brazil','Chile','Chile'],'sex':['male','female','male','female','male','female']})
dados_albania = dados[dados['country']=='Albania']
dados_albaniaSerá retornado um DataFrame somente com os dados da Albania.
| country | sex | |
|---|---|---|
| 0 | Albania | male |
| 1 | Albania | female |
Porém, dessa forma você consegue um DataFrame somente para um único país, caso queira fazer para todos os países, ficaria inviável armazenar em variáveis manualmente. Vamos então a um exemplo de como fazer para armazenar os DataFrames em um dicionário, para que seja possível localizar o DataFrame a partir do nome do país:
dicionario_paises = {}
for pais in dados['country'].unique():
dicionario_paises[pais] = dados[dados['country']==pais]
dicionario_paisesO código retorna o dicionário:
{'Albania': country sex 0 Albania male 1 Albania female, 'Brazil': country sex 2 Brazil male 3 Brazil female, 'Chile': country sex 4 Chile male 5 Chile female}
Foi criado inicialmente um dicionário vazio, nomeado dicionario_paises. Utilizei um loop for para percorrer todos os valores únicos da coluna 'country', com o uso do método unique(). Para cada um dos países únicos, foi salvo em um dicionário o DataFrame referente àquele país no valor e na chave o nome do país.
Você pode utilizar o dicionário para localizar o país de seu desejo. Exemplo para país Brasil:
dicionario_paises['Brazil']Que retorna:
| country | sex | |
|---|---|---|
| 2 | Brazil | male |
| 3 | Brazil | female |
Caso queira incluir um loop for para salvar diversos arquivos em csv para cada um dos países, fica bem simples.
for pais, dataframe in dicionario_paises.items():
dataframe.to_csv(f'{pais}.csv')Bons estudos!