Você está vendo a versão anterior da nova experiência da Alura que estamos preparando para você. Em breve, ela ganha uma identidade visual novinha totalmente pensada em potencializar seus estudos!



Olá, Pedro! Tudo bom?
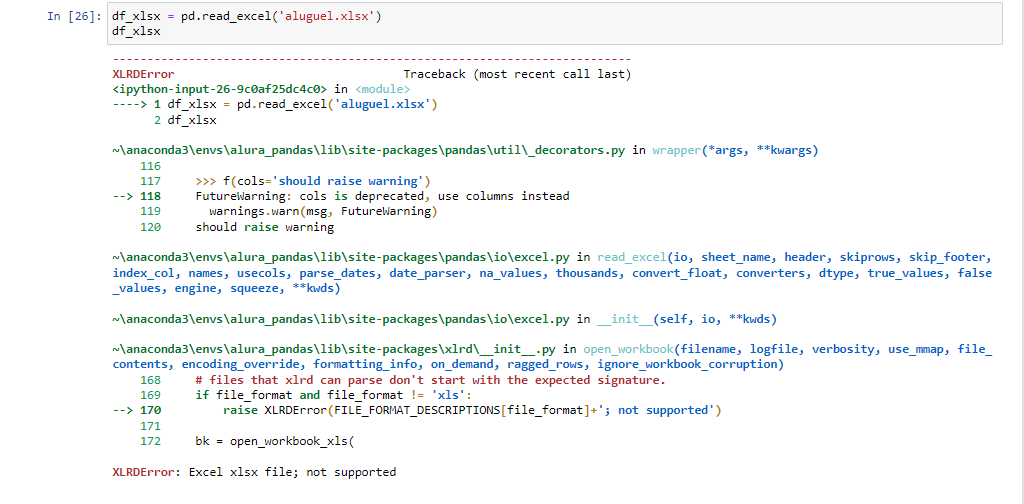
Para realizar a leitura de um arquivo excel, mais especificamente de um .xlsx é necessário informar o nome da tabela que você deseja analisar. Lembra que lá no Excel em um mesmo documento pode existir várias abas com tabelas diferentes? É exatamente isso que precisamos especificar. No nosso caso, podemos informar "0" ou então o parâmetro como None. E isso pode ser feito através da linha de código:
pd.read_excel('aluguel.xlsx', sheet_name = None)Se após isso ainda não funcionar, verifique se você possui a biblioteca xlrd instalada no seu ambiente virtual, onde ficam as bibliotecas do Anaconda. E uma maneira para garantir que está instalar, é executar em uma célula do notebook de maneira separada o comando de instalação:
!pip install xlrdE uma terceira saída, considerando uma atualização recente da biblioteca Pandas, seria trocar o engine utilizado para abrir o documento. Podemos intalar o pyopenxl, que é o responsável direto por abrir formatos novos do Excel, e depois utilizá-lo no pd.read_excel. Da seguinte maneira:
!pip install openpyxlpd.read_excel('aluguel.xlsx', engine='openpyxl')Se ainda tiver alguma dúvida, estou por aqui. Ótimos estudos e grande abraço!

Bom dia! Estou com o mesmo erro. Já tentei tudo o que foi oferecido aqui e ainda segue com a mesma mensagem "ImportError: Install xlrd >= 0.9.0 for Excel support" que outra coisa posso tentar? Valeu!
