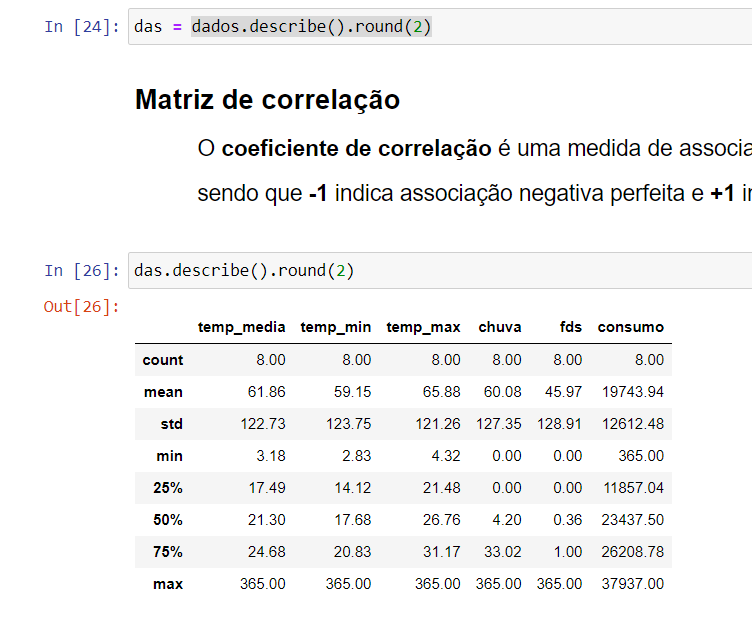
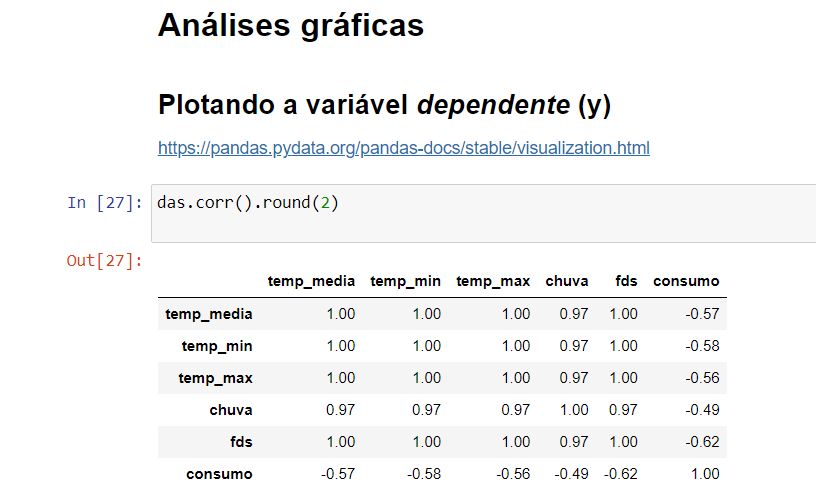
Pessoal sabem o pq esse erro ? Estou repetindo o passo a passo da aula e pra mim deu esse erro
--------------------------------------------------------------------------
ValueError Traceback (most recent call last)
Cell In[19], line 1
----> 1 dados.corr().round(4)
File ~\anaconda3\Lib\site-packages\pandas\core\frame.py:10054, in DataFrame.corr(self, method, min_periods, numeric_only)
10052 cols = data.columns
10053 idx = cols.copy()
> 10054 mat = data.to_numpy(dtype=float, na_value=np.nan, copy=False)
10056 if method == "pearson":
10057 correl = libalgos.nancorr(mat, minp=min_periods)
File ~\anaconda3\Lib\site-packages\pandas\core\frame.py:1838, in DataFrame.to_numpy(self, dtype, copy, na_value)
1836 if dtype is not None:
1837 dtype = np.dtype(dtype)
-> 1838 result = self._mgr.as_array(dtype=dtype, copy=copy, na_value=na_value)
1839 if result.dtype is not dtype:
1840 result = np.array(result, dtype=dtype, copy=False)
File ~\anaconda3\Lib\site-packages\pandas\core\internals\managers.py:1732, in BlockManager.as_array(self, dtype, copy, na_value)
1730 arr.flags.writeable = False
1731 else:
-> 1732 arr = self._interleave(dtype=dtype, na_value=na_value)
1733 # The underlying data was copied within _interleave, so no need
1734 # to further copy if copy=True or setting na_value
1736 if na_value is not lib.no_default:
File ~\anaconda3\Lib\site-packages\pandas\core\internals\managers.py:1794, in BlockManager._interleave(self, dtype, na_value)
1792 else:
1793 arr = blk.get_values(dtype)
-> 1794 result[rl.indexer] = arr
1795 itemmask[rl.indexer] = 1
1797 if not itemmask.all():
ValueError: could not convert string to float: '01/01/2015'