
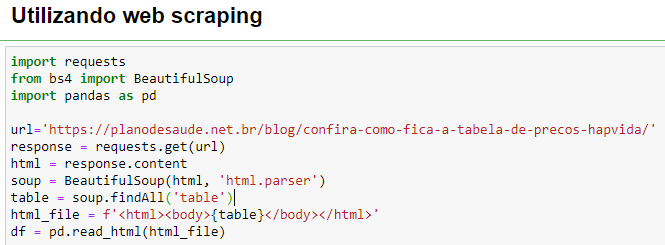
Na aula 7 do curso Python Pandas o instrutor executa um web scraping de um site na internet, utilizando o mesmo comando para o site que ele indicou e também para outros sites aleatórios da web, ocorre o erro: HTTP Error 403: Forbidden. Utilizei o jupyter notebook e o colab para executa o comando: import pandas as pd df_html = pd.read_html('https://www.federalreserve.gov/releases/h3/current/default.htm') df_html
Fiz uma pesquisa e parece que alguns sites permitem o scraping enquanto outros não. Seria essa a causa do erro? Vale lembrar que testei o mesmo comando com outros sites e o resultado foi o mesmo. O que está ocorrendo?


{kind=link}