Oii Leonardo, tudo certinho por ai? Espero que sim!
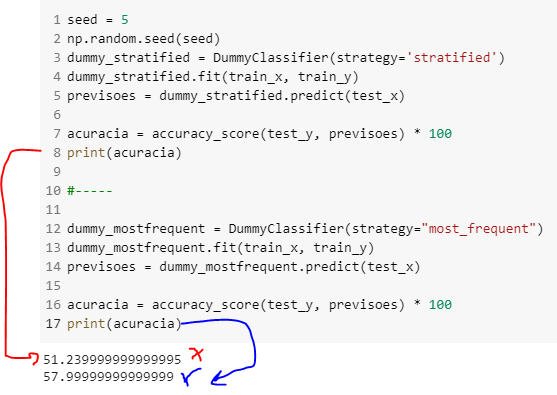
Seus resultados estão diferentes dos mostrados em aula pois o instrutor define o valor de SEED na parte do código que trata do LinearSVC, apenas, e quando você define novamente o valor de SEED na célula do dummy, ele altera os valores mesmo, é como se tivesse inicializado novamente. Existem algumas variedades de critérios de aleatoriedade que são respeitados quando usamos a SEED, para saber mais você pode ver na documentação do Python sobre o médoto random.
Seu problema pode ser resolvido seguindo a ordem dos fatores, que o instrutor fez em aula, então a definição de SEED ocorre na célula do LinearSVC(), vou deixar o código dessa parte abaixo.
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.svm import LinearSVC
from sklearn.metrics import accuracy_score
x = dados[["preco", "idade_do_modelo", "km_por_ano"]]
y = dados["vendido"]
SEED = 5
np.random.seed(SEED)
treino_x, teste_x, treino_y, teste_y = train_test_split(x, y, test_size = 0.25,
stratify = y)
print("Treinaremos com %d elementos e testaremos com %d elementos" % (len(treino_x), len(teste_x)))
modelo = LinearSVC()
modelo.fit(treino_x, treino_y)
previsoes = modelo.predict(teste_x)
acuracia = accuracy_score(teste_y, previsoes) * 100
print("A acurácia foi %.2f%%" % acuracia)
Depois, temos os códigos usando o método DummyClassifier. Outro ponto importante, que pode trazer alguns resultados diferentes pra ti durante esse curso, é que a biblioteca sklearn foi atualizada, então o valor de default do strategy, que passamos dentro do DummyClassifier, mudou desde que foi feito o curso. Isso não trás um impacto tão grande, mas pode trazer alguma diferença de resultados.
Espero que tenha te ajudado, mas qualquer outra dúvida, pode me chamar, ok?
Bons estudos ^^
Caso este post tenha lhe ajudado, por favor, marcar como solucionado ✓. Bons Estudos!