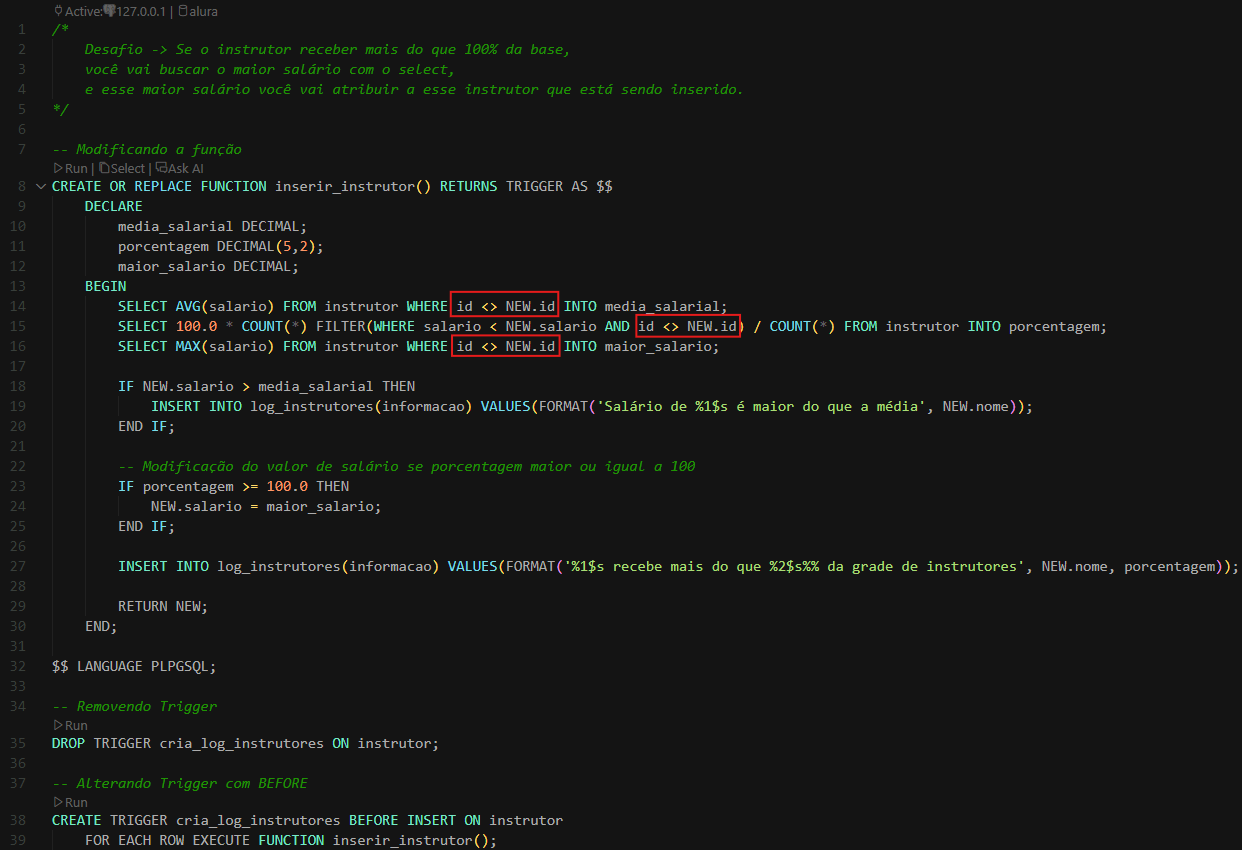
Agora que estamos usando o BEFORE, colocar " id <> NEW.id" não é mais necessário, certo?
Porque, pelo que eu entendi, os novos valores não são inseridos no início. A função faz todas as checagens e só depois insere os valores.
Você está vendo a versão anterior da nova experiência da Alura que estamos preparando para você. Em breve, ela ganha uma identidade visual novinha totalmente pensada em potencializar seus estudos!

Agora que estamos usando o BEFORE, colocar " id <> NEW.id" não é mais necessário, certo?
Porque, pelo que eu entendi, os novos valores não são inseridos no início. A função faz todas as checagens e só depois insere os valores.


Ei, Leonardo! Tudo bem?
Você está no caminho certo!
Em um trigger BEFORE INSERT, a variável NEW contém os dados do registro que está prestes a ser inserido, mas esse registro ainda não existe na tabela. O trigger é executado antes da inserção, permitindo que você verifique ou modifique os valores de NEW antes que eles sejam gravados. Como o registro não está na tabela durante a execução do trigger, qualquer consulta à tabela não inclui os dados de NEW. Então não há necessidade de usar id <> NEW.id para excluir o registro atual da consulta, já que ele simplesmente não está lá.
Por outro lado, em um trigger BEFORE UPDATE ou AFTER UPDATE, o registro já existe na tabela antes da atualização. Ao fazer uma consulta à tabela, como buscar o maior salário, o registro atual (com NEW.id) pode interferir no resultado se não for excluído. Aí, a condição id <> NEW.id é usada para ignorar o registro que está sendo atualizado, garantindo que a consulta considere apenas os outros registros.
Espero ter ajudado e qualquer dúvida, compartilhe no fórum.
Até mais, Leonardo!
Caso este post tenha lhe ajudado, por favor, marcar como solucionado!